ЕМЖСЃКБОЮФЕФжїЬтЪЧЭјвзДѓЪ§ОнHDFSЕФгХЛЏКЭЪЕМљЃЌЯТУцЛсДгШ§ИіЗНУцРДНщЩмЭјвздкДѓЪ§ОнДцДЂЯрЙиЕФЙЄзїКЭХЌСІЁЃ - ЭјвзДѓЪ§ОнЦНЬЈ
- HDFSдкЭјвзЕФЪЕМљМАЬєеН
- жиЕувЕЮёЗжЯэ
01 ЭјвзДѓЪ§ОнЦНЬЈ Эјвзв§ШыHadoopЪЎФъгагрЁЃПЊдДЪЧДѓЪ§ОнаавЕЕФЗЂеЙЧїЪЦЃЌЭјвзвВЪЧБОзХПЊдДПЊЗХЕФаФЬЌРДзіКУДѓЪ§ОнЁЃ
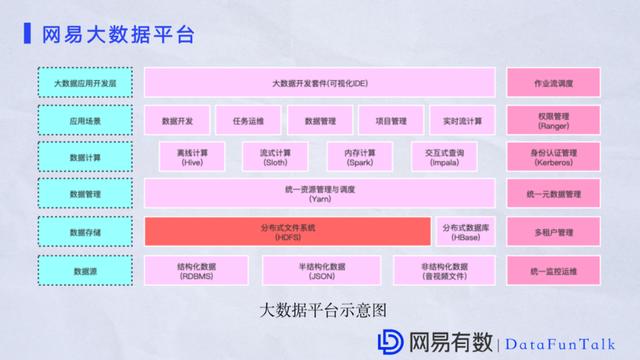
НќФъРДЫцзХвЕЮёЕФЗЂеЙЃЌЭјвзЪЕЯжСЫДѓЪ§ОнПчдЦВПЪ№ЃЌПчдЦЩњВњЃЌЮЊвЕЮёдкЩњВњаЇвцЩЯДјРДСЫКмЖрвцДІЁЃЩЯЭМЪЧЭјвзДѓЪ§ОнЦНЬЈЕФЪОвтЭМЃЌДгТпМЩЯЗжЮЊСљДѓВПЗжЃК ДѓЪ§ОнгІгУПЊЗЂВуЃКЬсЙЉСЫвЛаЉДѓЪ§ОнПЊЗЂЬзМўИјвЕЮёЩњВњЪЙгУЃЌЭЈГЃЪЧПЩЪгЛЏВњЦЗЁЃвЕЮёПЩвдЭЈЙ§вЛИіМђЕЅЕФSQLШЅВщбЏФГИіБэРяЕФЪ§ОнКЭздМКаДЕФJobШЮЮёЁЃ гІгУГЁОАВуЃКгыШЮЮёКЭЪ§ОнЯрЙиЕФГЁОАЃЌЬсЙЉСЫЪ§ОнПЊЗЂКЭЪ§ОнЙмРэЯрЙиЕФВњЦЗЁЃвЕЮёдкЦНЬЈжаЕФЪ§ОнвдМАШеГЃЕФИЈжњЙІФмЖМдкетвЛВуЪЕЯжЁЃБШШчВщПДжЎЧАдЫааЕФвЛаЉзївЕЃЌЪЙгУЕФФФаЉБэЕШЕШЁЃ Ъ§ОнМЦЫуВуЃКДѓЪ§ОнРыВЛПЊМЦЫуЃЌЭјвзЪЕЯжСЫЖржжМЦЫуРраЭЃЌР§ШчРыЯпЪЙгУHiveЃЌМЦЫуЪЙгУFlinkЃЌSparkКЭвЛаЉНЛЛЅадЕФВщбЏЁЃЩЯУцСНВуЬсНЛЕФШЮЮёОЙ§етВуХаЖЯРыЯпЛЙЪЧдкЯпКѓНјШыЕНЯТвЛВуЁЃ Ъ§ОнЙмРэВуЃКИїНзЖЮгаЭГвЛЕФзЪдДЕїЖШЃЌЭјвзбЁдёYARNРДНјааЕїЖШЃЌВЂзіСЫКмЖргХЛЏЁЃ Ъ§ОнДцДЂВуЃКHDFSЗжВМЪНДцДЂЁЃШчЙћгавЕЮёашвЊИпЭЬЭТЕФадФмЃЌНЈвщЪЙгУHBaseЁЃ Ъ§ОндДЃКДѓЪ§ОнзюПЊЪМЪЧдкДЋЭГЕФММЪѕЩЯЗЂеЙЖјРДЕФЃЌЫљвдгаКмЖрНсЙЙЛЏЕФЙиЯЕаЭЪ§ОнЁЃЫцзХвЕЮёЕФЗЂеЙЃЌВњЩњСЫКмЖрвєЪгЦЕЪ§ОнКЭJSONЪ§ОнетбљЕФАыНсЙЙЛЏЪ§ОнЃЌетаЉЖМЪЧПЩвддкДѓЪ§ОнЦНЬЈДђЭЈЕФЁЃ ЭЈГЃДѓЪ§ОнЦНЬЈЛЙАќРЈвЛаЉИЈжњЙІФмЃЌзївЕЕїЖШЪЙгУAzkabanЃЌЩэЗнШЯжЄЪЙгУKerberosЕШЕШЁЃСэЭтећИіЦНЬЈЕФдЊЪ§ОнЪЧЭГвЛНјааЙмРэЃЌдЫЮЌМрПиЩЯвВзіЭГвЛЙцЛЎЁЃ
ЕБЧАЭјвзДѓЪ§ЦНЬЈвбОЪЕЯжвкМЖДцДЂЃЌгЕгаЖрИіЛњЗПКЭЖрИіМЏШКБЃжЄЮёЪ§ОнВЛЛсЖЊЪЇЁЃЭЌЪБЮЊСЫАяжњвЕЮёвдНЯаЁЕФзЪдДЪЕЯжНЯКУЕФРћвцЃЌЭјвзЪЕааДцЫуЗжРыЃЌВЛдйШУвЕЮёЪмЯоЪ§ОнКЭМЦЫуАѓЖЈЁЃДцДЂвРОЩЪЧвдHDFSЮЊжїЁЃСэЭтЖдвЕЮёБШНЯЙиаФЕФГЩБОЮЪЬтЃЌЭјвзДѓЪ§ОнЦНЬЈЬсЕНЕФвЕЮёЩЯдЦЗНАИЪЙвЕЮёПЩвдИќМгзЈзЂЕФЗЂеЙЁЃ
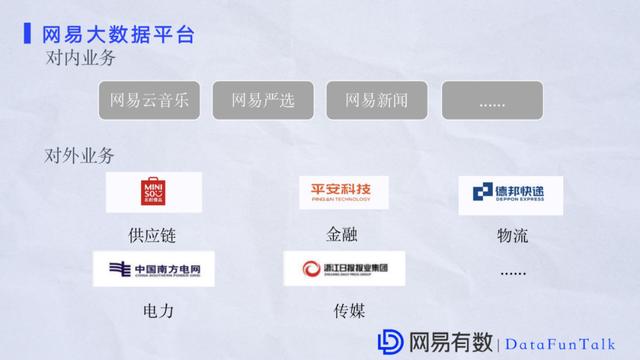
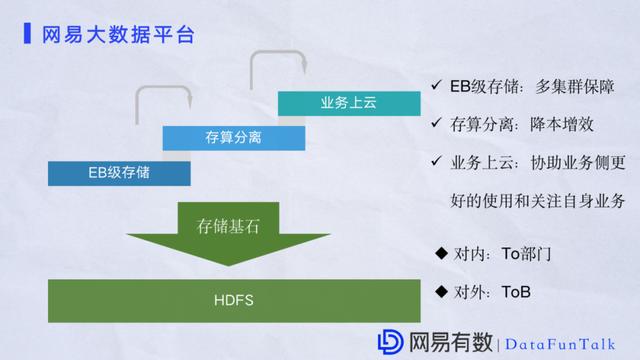
ФПЧАЭјвзДѓЪ§ОнЕЃШЮСЫМЏЭХФкЃЌШчЭјвздЦвєРжЁЂЭјвзбЯбЁЁЂЭјвзаТЮХЃЌКЭМЏЭХToBвЕЮёЃЌШчЙЉгІСДЁЂН№ШкЁЂЕчСІДЋУНЕШЕШЁЃЩЯУцСаОйЕФжЛЪЧвЛВПЗжЃЌЖрИіГЁОАвбОдкЪЙгУЮвУЧЕФЗўЮёВЂЧввбОГЩЙІТфЕиЁЃ 02 HDFSЪЕМљМАЬєеН НгЯТРДНщЩмHDFSЕФгІгУКЭгХЛЏЁЃЮвУЧЕФHDFSМИКѕЪЧКЭДѓЪ§ОнЦНЬЈЭЌЪБв§ШыЃЌОЙ§ЖрФъЕФММЪѕЗЂеЙдкАВШЋЁЂИпаЇЁЂЪЕМљЩЯЖМгаздМКЕФаФЕУЁЃ
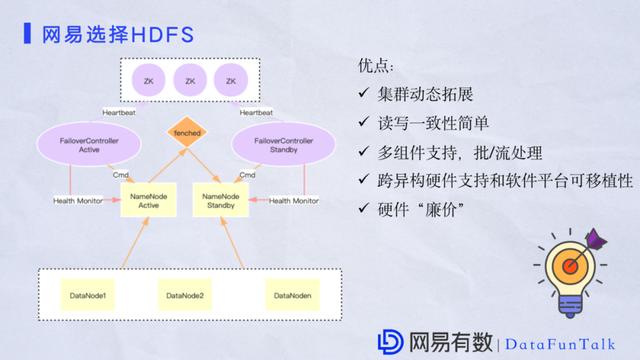
жкЫљжмжЊHDFSгаМИИіБШНЯгХауЕФЬиЕуЃЌетРяЛиЙЫвЛЯТHDFSЕФЛљДЁМмЙЙЁЃHDFSЭЈГЃгаСНИіжїНкЕуЃЌactive NamenNodeКЭstandby NameNodeЃЌВЂЧвЛЙАќКЌЖрИіDataNodeвЛЦ№РДЖдЭтЬсЙЉЗўЮёЁЃжїНкЕужївЊЪЧИКд№дЪ§ОнЙмРэКЭНгЪеПЭЛЇЖЫЧыЧѓЁЃШчЙћNameNodeЗЂЩњЙЪеЯЃЌгаHAЛњжЦПЩвдБЃжЄИпПЩгУЁЃЪ§ОнСїНјРДКѓЛсЗжХфИББОЗХжУгкВЛЭЌЕФЪ§ОнНкЕуЃЌетаЉЪ§ОнНкЕуЭЈГЃЛсгаздМКЕФВпТдДцДЂдкDataNodeЩЯЃЌЭМЩЯЪЁТдСЫJournalNodeНкЕуЁЃ е§ЪЧгЩгкетжжМмЙЙЃЌЮвУЧЪЕЯжСЫМЏШКЖЏЬЌРЉеЙЃЌПЩвдЖдФГИіМЏШКВЛЭЃжЙЗўЮёЕФЧщПіЯТНЋЦфЧсвзРЉеЙЕНЪ§АйИіНкЕуЃЌЩѕжСЪ§ЧЇИіНкЕуЁЃСэЭтHDFSЪЧвЛДЮаДШыШЮвтЖСЛњжЦЁЃЫцзХДѓЪ§ОнЕФЗЂеЙЃЌФПЧАHDFSЭъШЋПЩвдКЭЖрИізщМўНјааШкКЯЃЌБШШчЫЕHiveЁЂSparkЁЂFlinkЕШЕШЃЌКмШнвзОЭФмЪЕЯжЪЕЪБДІРэЃЌХњДІРэЁЃДЫЭтЃЌдкВПЪ№ЩЯЖдгВМўЕФвЊЧѓвВВЛЪЧЬиБ№ИпЁЃ
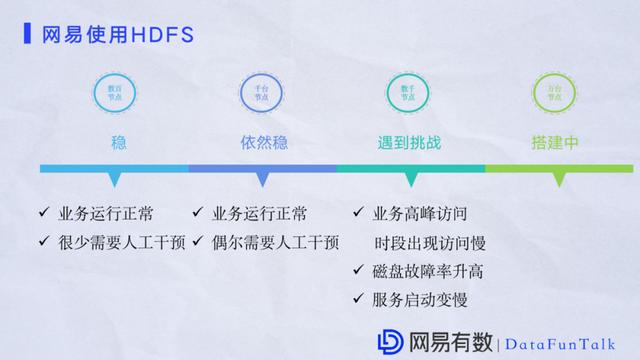
КЭДѓЖрЪ§ГЇМввЛбљЃЌЭјвздкЪЕМљHDFSЕФЙ§ГЬжавВОРњСЫЖрИіНзЖЮЁЃзюПЊЪМЪБЪ§АйИіНкдЫааЗЧГЃЮШЖЈЃЌЦНЪБКмЩйашвЊШЫЙЄИЩдЄЁЃКѓРДЫцзХвЕЮёЗЂеЙТ§Т§РЉШнЕНЧЇЬЈЙцФЃЁЃетИіЪБКђвЕЮёдЫааХМЖћашвЊШЫЙЄИЩдЄЁЃдкКѓРДвЕЮёРраЭвдМАгІгУдНРДдНЙуЃЌМЏШКЙцФЃЗЂеЙЕНЪ§ЧЇЬЈНкЕуЁЃДЫЪБвЕЮёЛсГіЯждкИпЗхЪБЖЮЯьгІНЯТ§ЕФЧщПіЃЌЭЌЪБПЩФмЛсГіЯжЪ§ОнНкЕудкФГИіЪБПЬЛЕХЬЕФЧщПіЁЃЫцзХЪ§ОндНРДдНЖрЃЌдЊЪ§ОнвВдНРДдНЖрЃЌжиЦєЪБМфвВЛсЯргІБфТ§ЁЃЭјвздкетИіЙ§ГЬжаВШЙ§КмЖрПгЁЃФПЧАЮвУЧЕФЗўЮёЗЧГЃЮШЖЈЃЌЫцзХЗўЮёдНРДдНЮШЖЈЕФЧщПіЯТЭјвзе§дкДюНЈЭђЬЈНкЕуЕФМЏШКЁЃ
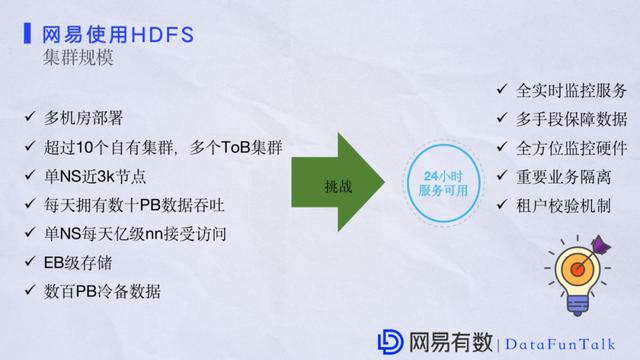
ФПЧАЭјвздкМЏШКЩЯгаЖрИіЛњЗПзіБЃеЯЃЌгаЖрИіздгаМЏШККЭЖрИіToBМЏШКвЕЮёЃЌВЂЧвЕЅИіNameSpaceвВГЌЙ§Ъ§ЧЇИіНкЕуЃЌвЕЮёЭЬЭТСПУПЬьДяЕНСЫЪ§ЪЎPBЁЃдкЗУЮЪЩЯЕЅИіNameSpaceКЭЕЅИіNameNodeПЭЛЇЖЫНгЪмЗУЮЪвбОДяЕНСЫвкМЖБ№ЃЌЭЌЪБдкРфШШММЪѕЩЯвВгаНЈЪїЁЃБШШчЯждкЭъШЋПЩвдЬсЙЉЪ§АйPBЙцФЃЕФРфБИМЏШКЭЌЪББЃжЄЫљгаЯпЩЯЗўЮёе§ГЃПЩгУЁЃетРяЛЙгавЛИіЬєеНЪЧБЃжЄЗўЮё24аЁЪБПЩгУЁЃЮвУЧЖдЗўЮёЭЈГЃЪЧзіШЋЪЕЪБМрПиЃЌЖдгВМўзіШЋЪЕЪБМрПиЃЌЖдвЛаЉживЊЕФвЕЮёзіИєРыЁЃ

ЖдгкHDFSЕФЬєеНРДЫЕЃЌгавЛаЉГЇЩЬзЈзЂгкМЏШКЃЌЛЙгавЛаЉГЇЩЬзЈзЂгкгВМўЁЃЮвУЧИљОнздМКЕФЗЂеЙЙцЛЎвдМАЪЕМЪГЁОАзмНсСЫЭјвзгіЕНЕФСНДѓЬєеНЃК - МЏШКЙцФЃдіГЄвдМАадФмДјРДЕФЬєеН
- Ъ§ОнВЛЖЯдіГЄвдМАЪ§ОнЦНКтЙмРэДјРДЕФЬєеН
ЫцзХвЕЮёЕФВЛЖЯЭиеЙЃЌУПФъживЊЕФвЕЮёЖМЛсдіМгЖрИіNameSpaceРДгІЖдвЕЮёЕФЭиеЙвдМАДДаТЃЌВЂЧвдкНкЕуЪ§ЩЯвВЛсЭиеЙЃЌР§ШчвєРжЁЂДЋУНУПФъЖМЛсдіМгКмЖраТЪ§ОнЁЃЮвУЧвВЛсВЛЖЈЦкДюНЈвЛаЉзЈгаМЏШККЭЙЋгаМЏШКЁЃжДааЙцФЃдіГЄЕФЭЌЪБвВашвЊЗўЮёЕФЮШЖЈдЫааЃЌжЛгаЗўЮёЮШЖЈдЫааЃЌвЕЮёВХПЩвдЪевцИќДѓЁЃЫцзХМЏШКЙцФЃЕФдіГЄЃЌЯргІЕФЪ§ОнвВЛсгаКмЖрЬхЯжЁЃМЏЭХФкВПгаКмЖрвЕЮёЪ§ОнУПИідТЖМЛсдіГЄЪ§PBЃЌЩѕжСЪЧ10PBЁЃдкЗхЖЮЪБЖдгкHDFSЃЌЙмРэЪ§ОнвВгаКмЖрЬєеНЃЌдкЙмРэЪ§ОнГЩБОЩЯвВЛсЯргІЕФдіМгЃЌБШШчгВМўГЩБОЃЌдЊЪ§ОнЙмРэГЩБОЕШЕШЁЃ
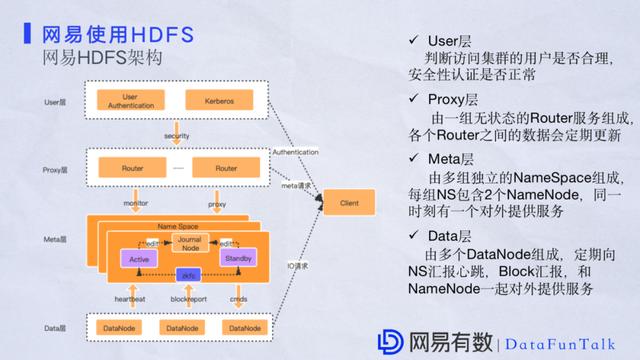
етЪЧЕБЧАЭјвзЕФHDFSМмЙЙЭМЃЌжївЊЪЧЗжЮЊЫФВуЃЌздЩЯЖјЯТЗжБ№ЪЧЃК гУЛЇВуЃКетВужївЊХаЖЯгУЛЇЗУЮЪЕФКЯРэадвдМААВШЋШЯжЄЃЌетПщЪЙгУKerberosНјааШЯжЄЁЃ ДњРэВуЃКжївЊНшМјRBFЗўЮёзіДњРэЃЌетПщЛсДюНЈЖрИіRouterгІЖдЗхжЕЕФЧыЧѓвдМАЦНЪБвЕЮёЕФдіСПЧыЧѓЃЌећИіRouterздЩэвВгаздМКИќаТЕФдіСПЪ§ОнЃЌБШШчЖЈЦкИќаТЃЌЖЈЦкИагІNameNodeЃЌНќЦкЕФзДЬЌЪ§ОнЕШЕШЁЃ дЊЪ§ОнВуЃКдЊЪ§ОнгУЖрИіNameSpaceзщГЩЃЌУПИіNameSpaceЭЈГЃгаСНИіNameNodeЃЌЭЌвЛЪБПЬСНИіNameNodeЛсЩшжУвЛИіжїНкЕуРДНгЪмПЭЛЇЖЫЕФЧыЧѓЁЃетПщКЭДњРэВуЪЧвЛЦ№ЕФЃЌвђЮЊПЭЛЇЖЫдкЗУЮЪЪБRouterЭЈГЃЛсгавЛИіДњРэжБНгАбЧыЧѓЯТЗЂЕНЯргІЕФNameNodeЩЯШЅЁЃ Ъ§ОнВуЃКЪ§ОнВугЩЖрИіDataNodeзщГЩЃЌЛсЖЈЦкЯђNameNodeЛуБЈаФЬјЁЂдіСПЪ§ОнЁЂBlockаХЯЂЕШЕШЃЌетПщжївЊИКд№КЭПЭЛЇЖЫЕФIOЧыЧѓЃЌЕБПЭЛЇЖЫдкЗЂЦ№ЧыЧѓЕФЪБКђЃЌЭЈГЃЛсШУПЭЛЇЩъЧывЛИіПЩгУЕФеЫЛЇЁЃдкЧыЧѓЪБЛсгХЯШОЙ§гУЛЇВузіАВШЋаЃбщЃЌаЃбщГЩЙІжЎКѓВХЛсКЭЯргІЕФRouterЗўЮёНјааНЛЛЅЃЌгЩRouterзіДњРэЃЌАбПЭЛЇЖЫЧыЧѓзЊЗЂЕНЯргІЕФNameNodeЩЯЁЃзюКѓДг RouterетБпФУЕНЯргІЕФЧыЧѓЕижЗКЭЪ§ОнвдМАDataNodeзіIOЭЈаХЃЌЕУЕНЯргІЕФЪ§ОнЁЃФПЧАетИіМмЙЙгаКмЖрКУДІЃЌПЩвдЪЕЯжЖЏЬЌЦНвЦЁЃNameNodeгавЛИіЕЅЕуадФмЦПОБЃЌетвЛЕуПЩвдЖдNameSpaceзівЛИіадФмЫЎЦНЭиеЙЁЃ

ЖдгкМЏШКЙцФЃдіГЄжївЊгаЫФИіЗНЯђЕФгХЛЏЁЃ ЗўЮёПьЫйЯьгІЃКвЛИіМЏШКЯывЊПьЫйЬсЩ§ЯьгІПЭЛЇЖЫЧыЧѓЪзЯШвЊБЃжЄЗўЮёЕФПьЫйЦєЖЏЃЌЛЙгавЕЮёЗУЮЪЪБжїНкЕуКЭDataNodeНкЕуЖМашвЊИпадФмЁЃ NameNodeадФмЭиеЙЮЪЬтЃКЕБNameSpaceЙмРэЕФЪ§ОндНРДдНЖрЪБNameNodeДцдкадФмЦПОБЃЌЫљвдвЊДгNameNodeадФмЦПОБГіЗЂЁЃМЏШКЙмРэвВЗЧГЃживЊЃЌгавЛаЉживЊЕФвЕЮёВЛгІИУКЭЦфЫћживЊвЕЮёЗХдквЛЦ№ЃЌвђЮЊгаЪБСНИіЭЌЕШживЊЕФвЕЮёЗХдквЛЦ№ПЩФмЛсгаЯрЛЅИЩШХЮЪЬтЃЌетИіЪБКђашвЊзівЛаЉЦРЙРЃЌАбЫћУЧЗХдкВЛЭЌЕФNameSpaceЩЯЃЌОљКтЬсЩ§NameSpaceЕФадФмЁЃ МЏШКМрВтФмСІЃКДгМЏШКРДЫЕЃЌМЏШКадФмЕФКУЛЕЦфЪЕЖдЫћЕФМрВтФмСІвВКмживЊЃЌБШШчНћжЙвьГЃСїСППЩвдЬсЩ§МЏШКадФмЁЃ вЕЮёЦРЙРЃКДгвЕЮёНЧЖШНјааГіЗЂЕФЛАЮвУЧашвЊКЭвЕЮёНјааЙВНЈЁЃЖдгкШЮКЮвЛИівЕЮёРДНВЃЌЪЧЗёНгФЩвЕЮёЦфЪЕвЊИљОнЕБЧАМЏШКдЫааЕФзДЬЌвдМАживЊадРДОіЖЈЁЃЫљвдЫЕвЊзіНгШыЧАЕФЦРЙРЃЌЛЙгаНгШыКѓЕФХаЖЯЕШЕШЁЃ
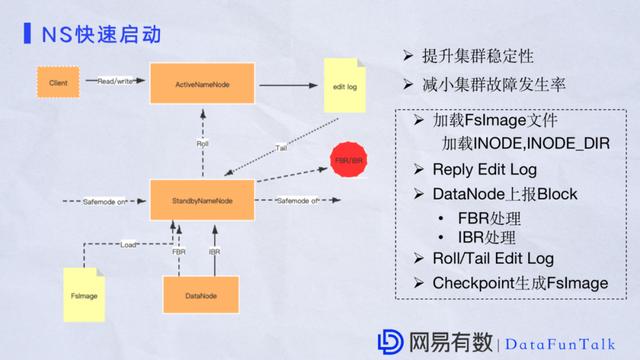
дкНщЩмNameSpaceПьЫйЦєЖЏгХЛЏЧАЃЌЯШРДЛиЙЫвЛЯТNameNodeЕФЦєЖЏСїГЬЁЃЕБвЛИіNameNodeЦєЖЏЪБЃЌЯШНјШыSafeModeНзЖЮЃЌИУnamenodeЪЕМЪЩЯБфГЩСЫstandy NameNodeЃЌНєНгзХЕБЧАNameNodeЛсМгдиБОЕидЊЪ§ОнЮФМўЃЌОЭЪЧFSImageЮФМўЁЃЭъГЩжЎКѓNameNodeЛсЛиЙіЮДМгдиЭъГЩЕФШежОЪ§ОнЃЌNameNodeНгЪеЫћЙмРэЕФвЛаЉDataNodeзЂВсЃЌжЎКѓDataNodeЛсНјааШЋСПЩЯБЈЃЌдіСПЩЯБЈЃЌЕБЧАЕФNameNodeвВЛсЖЈЦкЭЈжЊСэвЛИіactive NameNodeЃЌЩњГЩEditШежОЁЃетаЉEdit ШежОвВЛсВЂааБЃДцдкJournalNode жаЃЌЕБЧАNameNodeЛсЖЈЦкШЅJournalNodeЩЯРШЁEditLogЃЌИќаТздМКЕФФкДцЪ§ОнЁЃDataNodeдкетИіЙ§ГЬжаШчЙћгавЛаЉаТЕФЪ§ОнБфЛЏвВЛсПьЫйЯђNameNodeЗЂЫЭдіСПЪ§ОнЛуБЈЁЃжаЭОШчЙћNameNodeЗЂЯжТњзуСЫНгЙмЖЏзїЃЌБШШчФЌШЯЧщПіЯТЗЂЩњСЫ100ЭђИіЪТЙЪЃЌПЩФмЛсДЅЗЂЧаЛЛЁЃЕБЫљгаЕФDataNodeПщЛуБЈЕН99.999%ећИіЦєЖЏВХЫуЭъГЩЁЃNameNodeЦєЖЏЭъжЎКѓОЭПЩвдЭЫГіАВШЋФЃЪНЃЌетИіЙ§ГЬЪЧећИіNameNodeдкЦєЖЏжаЕФжївЊВНжшЁЃ дкетИіЙ§ГЬжагаМИИіЕиЗНБШНЯКФЪБЃЌвЛЪЧдкМгдидЊЪ§ОнЕФЪБКђЃЌвВОЭЪЧМгдиFSImageЃЌЖўЪЧNameNodeдкДІРэDataNodeЩЯБЈЪ§ОнЪБЃЌШчЙћЙмРэЕФЪ§ОнЗЧГЃЖрЪЧБШНЯТ§ЕФЁЃ

NameSpaceЦєЖЏгХЛЏЕФжївЊдвђОЭЪЧЬсЩ§МЏШКЮШЖЈадКЭНЕЕЭМЏШКЙЪеЯЗЂЩњТЪЃЌЮЊвЕЮёЗУЮЪзіадФмгХЛЏЃЌЬиБ№ЪЧЪ§ОнСПгавЛЖЈЙцФЃЪБИќвЊзігХЛЏВпТдЁЃ ИљОнЯпЩЯЪЕМљРДПДЃЌвЛЗндЊЪ§ОнжаЃЌОЭЪЧвЛЗнFSImageжаЃЌINODEКЭINODE_DIRЃЌетСНИіЮФМўЕФзмСПЛсеМЕН50%ЃЌЦфгрЕФВПЗжЛсдк50%ЩЯЯТЃЌВЂЧвећИіМгдиЙ§ГЬЖМЪЧДЎааДІРэЁЃдјОЗЂЩњЙ§вЛИіЯжЯѓЪЧдквЛИіжаМЖМЏШКМгди7вкдЊЪ§ОнПЩФмашвЊ20ЕН30ЗжжгЃЌетЪЧБШНЯТ§ЕФЁЃОЙ§ЮвУЧЕФЗжЮіЃЌПЩвдДгШ§ИіЗНУцзіадФмЬсЩ§ЃК - МгдидЊЪ§ОнЪБЃЌгШЦфЪЧМгдиINODEЃЌINODE_DIRПЩвдВЂааМгди
- дкаЃбщFSImageЪБЃЌдРДЪЧЕЅЕуДЎааЃЌПЩвдзіГЩВЂааДІРэ
- дкNameNodeНтЮіЭъдЊЪ§ОнжЎКѓгавЛИіИќаТФкДцЕФЖЏзїЃЌдРДвВЪЧДЎааДІРэЃЌЯждкЭъШЋПЩвдзіГЩВЂааДІРэ
етРяВЙГфСНЕуЃЌдкNameNodeеце§МгдиFSImageжЎЧАЃЌЖдгквЛИіБШНЯДѓЕФЮФМўЃЌаЃбщЪЧБШНЯКФЪБЕФЁЃЭЌЪБдкNameNodeНтЮіЭъжЎКѓЖдгкДЎааДІРэдЊЪ§ОнЪЧЗЧГЃЕЭаЇЕФЃЌЮвУЧвВзіСЫВЂааМгдиЁЃ
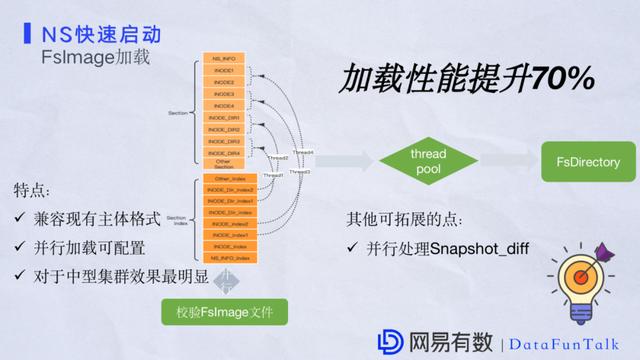
ЪзЯШЃЌаЃбщFSImageКЭМгдиFSImageИФГЩСЫВЂааМгдиЃЌдкМгдиЭъжЎКѓЃЌЖдМгдиINODEКЭINODE_DIRЮФМўКЭФПТМетСНВПЗжЪ§ОнЃЌЗжБ№ВЩгУЖрЯпГЬЕФаЮЪНЃЌШЛКѓНтЮіЪ§ОнвВВЩгУЖрЯпГЬЃЌЯпГЬГиЕФаЮЪНРДМгдиЕНФкДцжаЁЃетбљЛсМЋДѓЬсЩ§МгдиFSImageЕФадФмЃЌЛЙгавЛВПЗжЪЧВЂааМгдиКѓЪ§ОнЛсЩњГЩЯргІЕФИёЪНЃЌЕЋетИіИёЪНжїЬхВЛЛсБфЃЌетвЛПщЛсдіМгЯргІЕФМИВПЗжгУРДзіПижЦЁЃ етМИИігХЛЏЯюЕФЬиЕуЪЧЃКЕквЛЪЧМцШнСЫОЩЕФдЊЪ§ОнжїЬхЗчИёЃЌЕкЖўЕуЪЧЪЧЗёЦєгУВЂааМгдиетвЛЕуЪЧПЩХфжУЕФЃЌЛЙгадкЧаЛЛЩњГЩаТЕФFSImageЪБвВПЩвдЪЙгУМгдиОЩАцЕФFSImageаЮЪНШЅМгдиЁЃОЙ§ЯпЩЯбщжЄЃЌМгдиFSImageгХЛЏМЋДѓЕФЬсЩ§СЫадФмЃЌЭЈГЃФмЬсЩ§60%ЕН70%ЃЌетвЛПщвбОдкЖрИіДѓаЭМЏШККЭжааЭМЏШКжаЕУЕНГфЗжЕФбщжЄЃЌгШЦфЪЧдкжааЭМЏШКжаЃЌадФмЦеБщЛсИпгкетИіжЕЁЃдкFSImageжаЦфЪЕЛЙАќРЈЦфЫћЕФвЛВПЗжЪ§ОнЃЌБШШчЫЕIsTagЃЌАВШЋЯрЙиКЭSnapshotЯрЙиЕФдЊЪ§ОнаХЯЂЃЌетПщвВПЩвдВЮПМЩЯУцзіЕФгХЛЏНјвЛВНЬсЩ§FSImageЕФадФмЁЃ
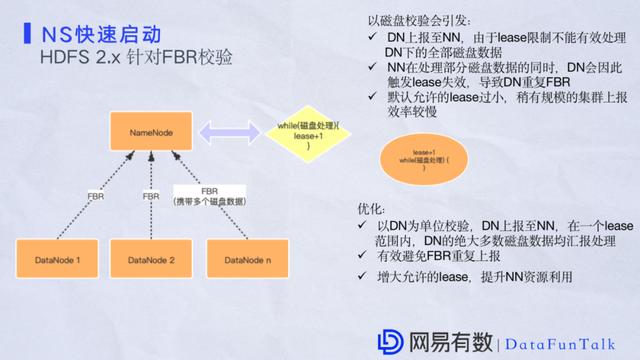
NameNodeДІРэDataNodeЩЯБЈЙ§ГЬжаЃЌгШЦфЪЧШЋСПЩЯБЈFBRетвЛПщЃЌдкдЪаэDataNodeЩЯБЈЪБашвЊЯШИјDataNodeЗЂЫЭвЛИіLeaseНјаааЃбщЃЌетЕуЪЧЭЈЙ§HeartBeatЩЯБЈДІРэЕФЃЌШЛКѓNameNodeАбlease IDЗжЗЂИјDataNodeжЎКѓЃЌDataNodeДЫЪБгаЛњЛсАбЪ§ОнЩЯБЈИјNameNodeЃЌФЌШЯЧщПіЯТетИіLeaseЪЧ6ЃЌЕБФГвЛИіDataNodeЛёЕУетИіLeaseКѓЛсАбДХХЬЪ§ОнвЛДЮадЗжЗЂЃЌДХХЬЪ§ОнЗЂЫЭЕНNamaNodeКѓNameNodeЛЙвЊЖдЩЯБЈЪ§ОнзівЛДЮаЃбщЃЌХаЖЯЕБЧАLeaseЪЧВЛЪЧПеЯаЃЌЕБЧАЩчЧјАцЪЧвдДХХЬаЃбщЮЊжїЃЌвВОЭЪЧЫЕЃЌМйШчвЛИіDataNodeга12ПщХЬЛђ24ПщХЬЃЌЩЯБЈжЎКѓЛсИљОнДХХЬНјаааЃбщЃЌШчЙћвЛИіDataNodeЩЯБЈ12ПщХЬжЎКѓЛсгХЯШДІРэЧА6ИіХЬЃЌЦфЫћЕФХЬОЭашвЊЕШЧАУцДІРэЭъжЎКѓдйНјааХХЖгДІРэЃЌетИіЙ§ГЬжаЛсгавЛаЉЮЪЬтЁЃЕквЛЪЧдкећИіЙ§ГЬжаЃЌDataNodeећИіДХХЬЪ§ОнВЛФмБЛгааЇДІРэЭъЃЌвђЮЊУПДЮжЛФмАДееФЌШЯЧщПіЯТДІРэ6ИіЃЌЦфЫћЕФШЋВПашвЊЕШД§ЁЃЕкЖўЪЧLeaseдкЯпЩЯЛсгаКмЖрЪЇаЇЕФЧщПіЃЌетИіЪЧвђЮЊLeaseФЌШЯжЛгаМИЗжжгЕФгааЇЪБМфЃЌЭЌвЛЪБМфПЩФмЛсгаКмЖрЕШД§ЃЌДІгквЛИіОКељзДЬЌЃЌетЪБLeaseгаПЩФмЪЇаЇЃЌDataNodeСэЭтЕФВПЗжУЛгазіЭъКѓУцОЭашвЊжиаТЩЯДЋвЛДЮЁЃетбљЕФЛАЛсМЋДѓЕФРЫЗбRPCзЪдДЁЃдкетжжЧщПіЯТЮвУЧНЋДХХЬаЃбщвдDataNodeЮЊЕЅЮЛаЃбщЃЌЕБШЋСПЪ§ОнЩЯБЈжЎКѓLeaseЛсБЛБъзЂвЛДЮЃЌШЛКѓNameNodeдкДІРэЭъDataNodeДХХЬжЎКѓОЭВЛдйзіЬиЪтДІРэСЫЁЃетбљзігаЖўЕуКУДІЃЌЕквЛЪЧDataNodeШЋСПЩЯБЈЕНNameNodeжЎКѓдквЛИігааЇЦкЕФLeaseЗЖЮЇжЎФкDataNodeЕФОјДѓЖрЪ§ДХХЬЖМЛсБЛДІРэЃЌГ§ЗЧЖгСаВЛЙЛЁЃЕкЖўЪЧФмгааЇБмУтDataNodeжиИДЩЯБЈЕФЮЪЬтЃЌетвЛЕуОјЖдФмЬсЩ§RPCадФмЁЃдкЪЕМЪЩњВњЕБжаЭЈГЃЛЙЛсзівЛаЉХфжУЃЌАбШЋСПLeaseжЕЕїДѓЃЌОпЬхЩЯЕїЕНЖрДѓашвЊИљОнЕБЧАЕФМЏШКРДШЗЖЈЃЌетЭЌбљЖдNameNodeзЪдДРћгУТЪгаБШНЯДѓЕФЬсЩ§ЁЃ
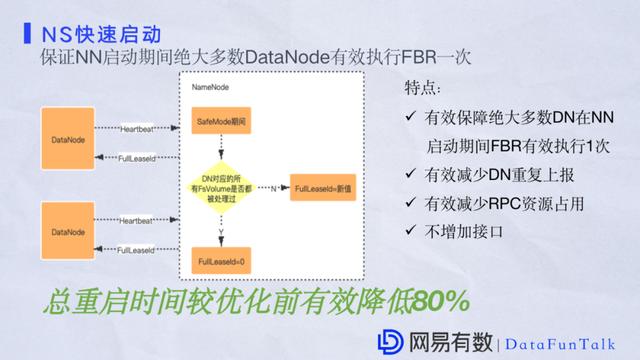
дкДѓаЭМЏШКЩЯЃЌЭЈГЃдЊЪ§ОнЕФСПЛсБШНЯЖрЃЌБШНЯДѓЁЃNameNodeЕФЦєЖЏЪБМфПЩФмЛсБШНЯГЄЁЃвЛИіDataNodeЦєЖЏжЎКѓЃЌУПИєвЛЖЮЪБМфжиИДЩЯБЈвЛДЮШЋСПЪ§ОнЕНNameNodeЃЌдјОЯпЩЯЗЂЩњЙ§ЩйСПЕФDataNodeОЭДЅЗЂЩЯБЈЃЌвЛИіжмЦкЙ§СЫвдКѓЫћЛЙЛсНјааЩЯБЈЃЌЕЋNameNodeдкетжжЧщПіЯТЛсгавЛаЉЯожЦЁЃNameNodeдкЦєЖЏжмЦкФкЃЌгШЦфЪЧдкSafeModeЦкМфЃЌDataNodeЩЯБЈЪ§ОнЪЧВЛЛсБЛNameNodeНјааЖўДЮДІРэЕФЃЌетЪЧвЛИіЗЧГЃжЕЕУЙизЂЕФЮЪЬтЁЃгШЦфЪЧЕквЛЕуЃЌКмРЫЗбRPCДЋЪфзЪдДЃЌШЛКѓЪ§ОнСПКмДѓЕФЧщПіЯТДњМлвВЛсЗЧГЃДѓЁЃЕкЖўЕуЪЧЗЂЩњдкDataNodeШЋСПЩЯБЈЕФЪБКђЃЌЛсИњЦфЫћЮДЩЯБЈЕФDataNodeзіМЗеМЃЌжиИДЩЯБЈЛсеМгУЦфЫћЖрВузЪдДЃЌетЪБЛЙгаКмЖрБОРДгІИУЩЯБЈЕФDataNodeЕУВЛЕНМАЪБДІРэЁЃдкетПщЕФгХЛЏЗНЗЈЪЧдкNameNodeЕФЦєЖЏЙ§ГЬжаШчЙћDataNodeШЋСПЩЯБЈБЛгааЇДІРэЙ§вЛДЮЃЌDataNodeОЭВЛашвЊБЛдйДЮДІРэСЫЁЃетбљзігаМИИіКУДІЃК - гааЇБЃеЯОјДѓЖрЪ§DataNodeдкNameNodeжиЦєЦкМфШЋСПЩЯБЈБЛгааЇДІРэвЛДЮЁЃ
- гааЇБмУтDataNodeжиИДЩЯБЈЁЃ
- НЯгкгХЛЏжЎЧАМЋДѓМѕЩйСЫRPCзЪдДЕФРЫЗбЁЃ
етРявЊзХжиЫЕУївЛЕуЕФЪЧећИіЙ§ГЬВЛашвЊдіМгШЮКЮНгПкЃЌдвђЪЧDataNodeдкЪЧЗёБЛдЪаэШЋСПЩЯБЈЦкМфNameNodeгавЛИіLeaseШЯжЄЃЌЩчЧјАцвВЪЧетУДзіЕФЁЃШЛКѓNameNodeЖЫШчЙћЗЂЯжгаПеЯаЕФЧщПіЯТОЭЛсЯђDataNodeЗЂЫЭвЛИіLeaseЃЌDataNodeФУЕНетИіLeaseОЭНјаавЛДЮШЋСПЩЯБЈЃЌећИіЙ§ГЬЪЧЭЈЙ§аФЬјДЅЗЂЕФЁЃЖдгкдкЦєЖЏгХЛЏетвЛПщГ§СЫЩЯУцетМИИіВПЗжжЎЭтЃЌЮвУЧЛЙзіСЫЦфЫћЕФЙЄзїЁЃБШШчNameNodeЖЫЙигкШЋСПКЭдіСПЖгСаЕФгХЛЏЃЌетвЛЕудкЩчЧјАцРяЪЧУЛгаЕФЁЃЛЙгаЪЧЖдаоИДЕФгааЇПижЦЃЌвђЮЊcheckpointдЩњАцБОЛсБШНЯПьЃЌгШЦфЪЧвЕЮёСПБШНЯДѓЕФЧщПіЯТжиЦєЪБcheckpointЛсПьЫйДЅЗЂЁЃдйОЭЪЧдкeditLogЙіЖЏКЭРШЁЕФЪБКђЃЌЮвУЧвВзіСЫвЛаЉгааЇЕФПижЦЃЌВЂЧвЖдгкDataNodeЖЫдіСПЩЯБЈвВашвЊзівЛаЉбгГйДІРэЁЃдкећИіNameNodeжиЦєЪБМфЯрНЯгкгХЛЏФмЬсЩ§80%ЕФадФмЁЃ
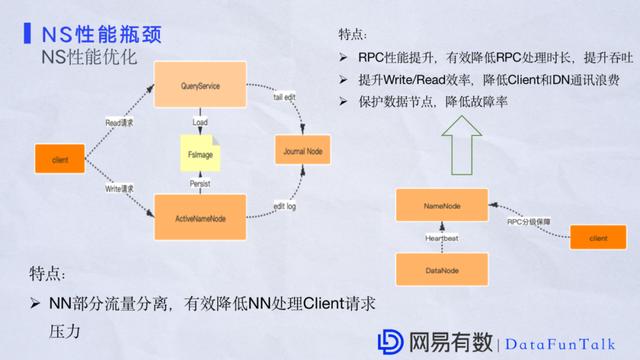
ЯТУцНщЩмNameSpaceЕФадФмгХЛЏЃЌNameSpaceадФмгХЛЏдкећИіHDFSЗЖЮЇжЎФкЪЧЗЧГЃживЊЕФЁЃгХЛЏЕФЛАЦфжагаСНВПЗжКмживЊЁЃ ЕквЛЪЧЙигкдкПЭЛЇЖЫЖСаДЧыЧѓЪБЃЌвЕЮёЖЫЭЈГЃЪЧДгNameNodeПЊЪМЃЌетРягаЪБКђNameNodeЛсГіЯжЯьгІБфТ§ЕФЧщПіЃЌЭЈГЃдквЕЮёСПБШНЯДѓЕФЧщПіЯТЃЌЛЙгаNSЙмРэЪ§ОнБШНЯЖрЕФЪБКђЁЃгХЛЏзіЗЈЪЧНЋВПЗжСїСПЗжРыГіШЅаЮГЩвЛИіЕЅЖРЕФЗўЮёЃЌЖЈЦкМгдиFSImageЃЌИќаТEditLogЁЃетРяАбвЛаЉВщбЏЙІФмДгдЩњЕФNameNodeЗжНтГіШЅЃЌетбљПЩвдгааЇЛКНтNameNodeбЙСІЁЃФПЧАвбОдкЖрИіМЏШКЩЯЕУЕНГфЗжЕФбщжЄЁЃ ЕкЖўЕуЪЧЖдNameNodeЕФRPCЗжМЖБЃеЯЛњжЦЁЃдкRPCЖдФкПижЦЩЯИФСМСЫгХЯШМЖЖгСаЃЌетФмгааЇЛКНтRPCЕФзшШћЁЃВЛЙ§етРягавЛаЉжЕЕУзЂвтЕФЕиЗНЃЌОЭЪЧдкФГаЉМЏШКЯТашвЊЖджиЕугУЛЇЕФЧыЧѓзізуЙЛЕФБЃеЯЃЌЮвУЧВЩгУдЄСєГізЪдДЕФЗНЗЈЕЅЖРДІРэЁЃетПщЕФЛАОЭФмКмКУЕиТњзуживЊгУЛЇЃЌвВФмОљКтЙмРэПЭЛЇЖЫЕФЧыЧѓЁЃетЪЧЖдRPCадФмЕФЧщПіЃЌЩЯУцСНИіЖМЪЧЖдадФмгХЛЏЯрЙиЕФЬиЕуЁЃ
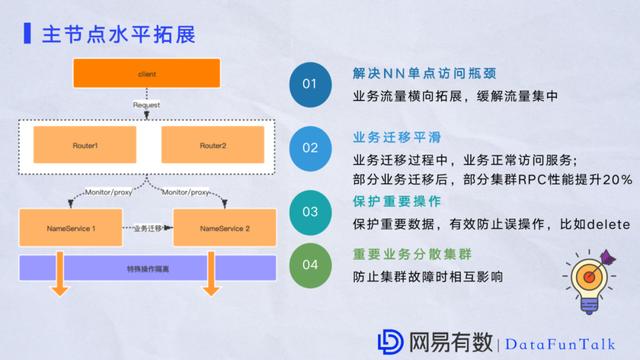
HDFSзїЮЊвЛИіЗжВМЪНДцДЂВњЦЗЃЌЕЅNameSpaceадФмвЛжББЛШЫкИВЁЃЌгШЦфЫцзХЪ§ОнСПдНРДдНДѓNSСїСПЙ§гкМЏжаГіЯжЗУЮЪУЋДЬЕФзДЬЌЁЃвђЮЊNameNodeЕФГадиСІзмЪЧгаЯоЕФЃЌдкетИіЧщПіЯТЧЈвЦЃЌИєРывЕЮёвВВЛШнвзЃЌетжжЧщПіОЭв§ШыСЫIBFЛњжЦЃЌвВОЭЪЧServerЕФСЊАюЛњжЦЁЃОЩАцБОЕФСЊАюЛњжЦжївЊЪЧдкПЭЛЇЖЫЙвдивЛИіЙвдиБэЪЕЯжЗУЮЪгГЩфЁЃRouterЕФЛњжЦНЯОЩАцЕФСЊАюЛњжЦдкServerЖЫеце§зіЕНСЫЖдвЕЮёЕФШЋЭИУїЃЌRouterЕФServerЖЫвВЛсЖЈЦкИажЊNameNodeзДЬЌЃЌМйШчЫЕФГИіNameNodeДгactiveзДЬЌБфГЩstandbyзДЬЌЃЌећИіЙ§ГЬRouterЛсКмПьжЊЕРЃЌвђЮЊRouterЗўЮёЛсЖЈЦкКЭNameNodeНјааЭЈбЖЃЌИажЊЕНNameNodeЕФзДЬЌЁЃетбљФГвЛИівЕЮёЯывЊЛЛвЛИіМЏШКРДНјааЗУЮЪЃЌвЕЮёЖЫВЛашвЊзіЬЋЖрИФБфЃЌжЛашвЊЮвУЧдкЗўЮёЖЫзівЛаЉИќаТЛђепИФБфЃЌетЖдећИівЕЮёРДЫЕЪЧЗЧГЃЭИУїЕФЁЃИќживЊЕФЪЧRouterЗўЮёФмЗЧГЃгааЇЕФЬсЩ§ЕЅNameSpaceадФмЁЃЮвУЧвВПЩвдЭиеЙЖрИіNameSpaceМЏШКЃЌЭЈЙ§вЛИіRouterРДНјааЙмРэЁЃдйепЮвУЧПЩвдНЋвЕЮёЦЕЗБЕФЧЈвЦЕНЦфЫћЕФNameSpaceЩЯЃЌећИівЕЮёвВЪЧЮоИажЊЕФЁЃОЙ§ЪЕМљЃЌдквЛаЉживЊЕФвЕЮёНјааЧЈвЦКѓЃЌЖддМЏШКRPCадФмжСЩйга20%ЕФЬсЩ§ЁЃдкRouterЕФЛљДЁЩЯЃЌвВзіСЫвЛаЉИФдьадЕФгХЛЏЃЌБШШчдкNameSpaceетвЛВуЃЌвЕЮёЯывЊзівЛаЉживЊЕФВйзїЃЌвВНјааСЫвЛаЉИєРыЃЌР§ШчdeleteВйзїЃЌетбљЪЧЮЊСЫЗРжЙвЕЮёЮѓВйзїЃЌвВЭЌЪБЪЧЖдживЊЪ§ОнНјааБЃЛЄЃЌдкNameSpaceВуЬсЙЉСЫвЛИіЬиЪтБЃЛЄЛњжЦЃЌЖдвЕЮёНјааЫЋВуБЃЛЄЃЌетЕуЖдЩчЧјАцБОРДЫЕЪЧвЛИіБШНЯДѓЕФДДаТЕуЁЃ
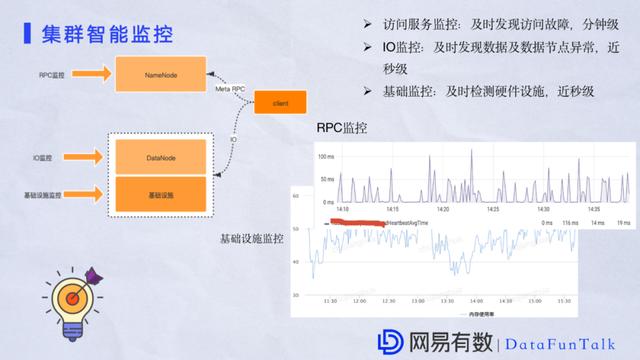
дкМЏШКЕФгХЛЏЗНУцЃЌГ§СЫШэМўадФмвдЭтМрПивВЪЧЗЧГЃживЊЕФвЛЕуЁЃЮвУЧЭЈЙ§MatrixжИБъКЭздбаНХБОЖдЕБЧАе§дкдЫааЕФЗўЮёзіШЋЗНЮЛМрПиЃЌАќРЈЖдИїИіЗўЮёЃЌRPCЕФМрПиЁЃвЛЕЉRPCГіЯжвьГЃЃЌБШШчЖгСабгГйИпЃЌHandlerбгГйИпЃЌОљФмПьЫйЗЂЯжЮЪЬтЁЃЛЙгаОЭЪЧЖдIOЕФМрПиЃЌБШШчФГвЛИіDataNodeЕФIOЗЧГЃИпЃЌвВФмПьЫйЗЂЯжЁЃСэЭтЖдгквЛаЉЛљДЁЩшЪЉЃЌР§ШчcpuИпЛЙгаФкДцИпЖМПЩвдзіЕНУыМЖЗЂЯжЁЃШчЭМжаЖдNameNodeЖЫЕФDataNodeаФЬјДІРэКФЪБЃЌЦНОљЪЧЪЎМИКСУыЁЃ
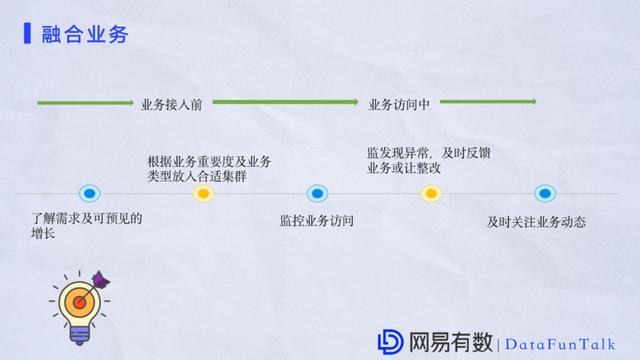
дкЙизЂМЏШККЭЯЕЭГБОЩэЕФЭЌЪБвЕЮёвВЪЧКмживЊЕФвЛВПЗжЁЃвђЮЊЙмРэЕФвЕЮёСПБШНЯЖрЃЌНкЕуЪ§вВБШНЯЖрЃЌвЕЮёЕФШкШыБОжЪЩЯИњЮвУЧЪЧЯрИЈЯрГЩЕФЁЃОйИіР§згЃЌФГЬьЮвУЧНгЪмСЫвЛИівЕЮёашЧѓЃЌвЛПЊЪМЮвУЧЖдвЕЮёашЧѓУЛгаГфЗжСЫНтЃЌПЩФмЛсНЋетИівЕЮёДцгкФГвЛИіживЊЕФМЏШКжаЃЌжЎКѓПЩФмдкФГвЛЪБПЬетИівЕЮёЛсВњЩњБШНЯДѓЕФСїСПгАЯьЦфЫћвЕЮёЁЃетжжЧщПігІИУБмУтЃЌЫљвддкНгФЩвЕЮёЪБашвЊзіКУЕФвЛЕуЪЧМАЪБСЫНтвЕЮёашЧѓвдМАПЩдЄМћЕФдіГЄЃЌИљОнвЕЮёЕФживЊадвдМАвЕЮёРраЭЗХШывЛИіКЯЪЪЕФМЏШКжаЁЃЦНЪБдкДюНЈМЏШКЕФЪБКђвВвЊЧјЗжзЈгаМЏШККЭЙЋгаМЏШКЃЌдкНгФЩвЕЮёжЎКѓвВзіКУЖдећИівЕЮёЕФМрПиЁЃШчЙћЗЂЯжвьГЃааЮЊЃЌвЊМАЪБНјааЗДРЁЁЃдквЕЮёНјРДжЎКѓвЊЙизЂвЕЮёЖЏЬЌЃЌОЁПЩФмСЫНтвЕЮёзпЯђЁЃ
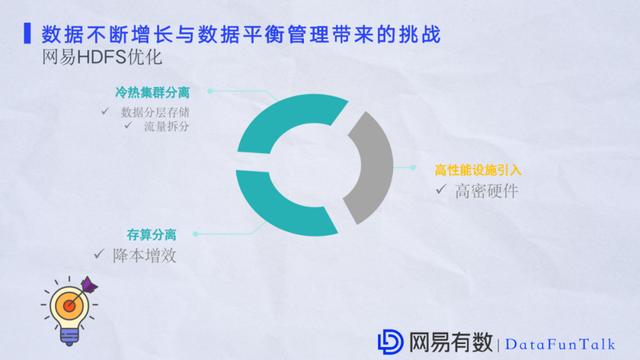
ЩЯУцНщЩмЮвУЧдкМЏШКдіГЄКЭМЏШКадФмЕФЩЯЕФОбщЃЌЯТУцДгЪ§ОнЗНУцзівЛаЉЗжЯэЁЃдкЙизЂМЏШКдіГЄЕФЭЌЪБвВашвЊЙизЂЪ§ОндіГЄЃЌМЏШКдіГЄвтЮЖзХЪ§ОнСПвдМАЗУЮЪСПЛсдіМгЃЌЯрЗДЪ§ОндіГЄвВЛсв§Ц№ЖдМЏШКЕФЙизЂЁЃЭјвздкЪ§ОндіГЄвдМАЪ§ОнЙмРэвВгаКмЖргХЛЏаФЕУЃЌжївЊЪЧШ§ИіЗНЯђЃК ЗжВуЙмРэЃКдкЪ§ОнНЈЩшЗНУцЃЌЮвУЧЖдЪ§ОнзівЛИігааЇВ№ЗжЃЌЗжВуЙмРэЃЌЗжБ№ДюНЈРфМЏШККЭШШМЏШКгІЖдРфЪ§ОнКЭШШЪ§ОнЁЃ ДцЫуЗжРыЃКдкЙмРэГЩБОЩЯЃЌЮвУЧЪЙгУДцЫуЗжРыРДНЕБОдіаЇЁЃ в§ШыИпУмгВМўЃКЮЊСЫНјвЛВНЬсЩ§МЏШКадФмв§ШыИпадФмЩшЪЉЃЌБШШчЫЕвЛаЉИпУмЕФгВМўЁЃ
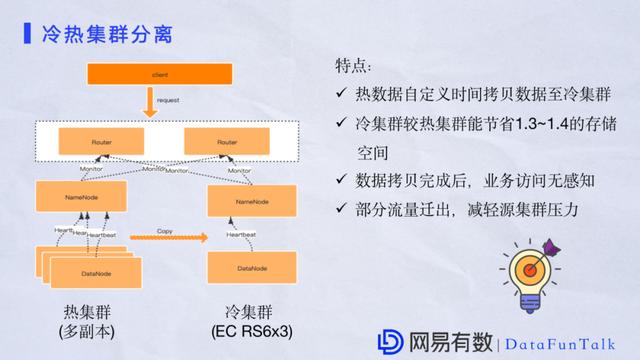
вЛИіМЏШКЕФЪ§ОнСПДѓСЫжЎКѓдйМгЩЯЖрИББОЛњжЦЃЌгВМўЕФГЩБОвВЛсдіМгЕФБШНЯПьЃЌЮвУЧЛсЗЂЯжвЛаЉЮЪЬтЃЌБШШчвЛаЉЪ§ОнЕФЪЙгУТЪЦфЪЕВЂВЛИпЃЌгаЕФЪ§ОнПЩФмвЛИідТАыИідТвВЗУЮЪВЛСЫМИДЮЁЃЛЙгаЧщПіЪЧвЕЮёДцЕФЗЧживЊЕФЪ§ОнвВЪЧЪЙгУЖрИББОБЃДцЃЌетбљадМлБШВЛИпЁЃЮЊСЫНЋИќМггагУЕФЪ§ОнЗХдкКЯЪЪЕФМЏШКЩЯУцЃЌЮвУЧЙцЛЎСЫРфШШМЏШКЗжБ№ДцЗХадМлБШИпЕФЪ§ОнКЭВЂВЛЬЋИпЕФЪ§ОнЁЃШШЪ§ОнЭЈГЃЛЙЪЧвдЖрИББОЕФаЮЪНЃЌРфЪ§ОнЪЙгУECРДНјааБЃДцЃЌЪЙгУRS6x3ВпТдЃЌОЭЪЧНЋ6ИідЊЪ§ОнПщЩњГЩ3ИіМгУмПщЁЃРфМЏШКОЙ§ЯпЩЯбщжЄЃЌжСЩйНкЪЁ1.3ЕН1.4ЕФвЛИіДцДЂПеМфЁЃдкНЋЪ§ОнДгШШЪ§ОнЕМШыЕНРфЪ§ОнетИіЙ§ГЬжаЮвУЧЛЙзіСЫвЛаЉИЈжњВњЦЗжЇГжздЖЈвхПНБДЃЌБШШчПЩвдАДжмЃЌАДаЁЪБЃЌЖјЧвећИіПНБДЙ§ГЬжаЖМгаRouterЛњжЦжЇГХЃЌБЃжЄећИівЕЮёЕФЗУЮЪЪЧЮоИажЊЕФЁЃЪ§ОнСїСПЧЈвЦЕНСэвЛИіМЏШКжЎКѓМѕЧсдМЏШКЕФЗУЮЪбЙСІЃЌетВПЗждкЪЕМљжавбОЕУЕНГфЗжбщжЄЁЃ
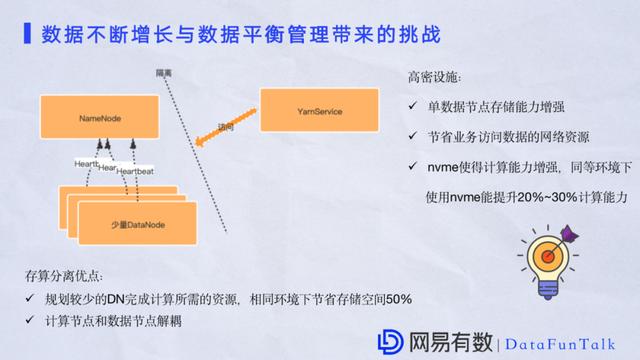
ЫЕЦ№МЦЫуВЛЕУВЛЬсЕНHadoopЕФYARNЁЃКмЖрМЦЫузщМўБШШчHiveЃЌSparkЃЌЯТВуЖМвЊвРЭагкYARNРДЕїЖШЯргІЕФTaskЁЃдкУЛгаНјааДцЫуЗжРыжЎЧАЦфЪЕЪЧгавЛаЉШБЕуЕФЃЌЕквЛИіШБЕуЪЧДцДЂНкЕуРЫЗбЃЌвђЮЊгааЉзЪдДВЛФмБЛЭъШЋРћгУЁЃЕкЖўИіШБЕуЪЧМЦЫуНкЕуВЛФмЭъШЋРћгУФкДцКЭCPUзЪдДЁЃ ДцЫуЗжРыММЪѕЃЌЪЙгУИќЩйЪ§ОнЕФЪ§ОнНкЕузЪдДгУгкМЦЫуНкЕуЃЌетбљгаКмЖрКУДІЃКЕквЛЪЧзЪдДРЫЗбБШНЯЩйЃЌЖдгкМЦЫуНкЕуПЩвдИќМгГфЗжРћгУећИіЕЅЛњзЪдДЁЃЛЙгаЪЧДцДЂПеМфвВЛсгаЯргІЕФдіМгЁЃАбЯрЭЌЛЗОГЯТдРДДцДЂЕФЪ§ОнвЦРДзізЈУХЕФДцДЂдкЯжНзЖЮЭъШЋПЩааЁЃ дкЪ§ОнЙмРэЩЯЮвУЧЛЙв§ШыСЫИпУмЩшБИЃЌвЛИіЪЧдкЪ§ОнНкЕуDataNodeЖдДцДЂзідіЧПЃЌдкIOЕФНЧЖШЯТЭјТчРћгУТЪИќИпЃЌЛЙгаЪЧв§ШыNVMEетбљЕФЩшБИЃЌвђЮЊNVMEНЯгкДЋЭГSSDХЬЦфгаадФмЩЯЕФгХЪЦЃЌБШШчдкЪ§ОнДЋЪфЩЯОпгаЕЭбгЪБЃЌЛЙгаВЂааадЁЃСэЭтдкЭјТчаджЪЩЯИњДЋЭГSSDЯрБШЯожЦвВаЁСЫЁЃетИідкЪЕМљЙ§ГЬжаЯрЭЌЛЗОГЯТЪЙгУNVMEПЩвдгааЇЬсЩ§20%вдЩЯЕФМЦЫуФмСІЁЃ

ЖдгкHDFSЕФадФмРДЫЕЃЌЙизЂЕуВЛЪЧДгЕЅвЛЗНУцЃЌашвЊДгЖрИіНЧЖШНјааГіЗЂЁЃетРяСаОйвЛаЉдкШеГЃЪЙгУЃЌбаЗЂКЭгХЛЏЙ§ГЬжаашвЊзЂвтЕФЕуЃК ЛЎЗжвЕЮёЃКМЏШКЙцЛЎЗНУцНЈвщАДееДѓвЕЮёНјааЛЎЗжЃЌПЩвдЧјЗжзЈгаМЏШККЭЙЋЙВМЏШКЃЌзЈгаМЏШКЭЈГЃЪЧЮЊФГаЉДѓЕФвЕЮёЛђепЫЕживЊЕФвЕЮёРДНјааЗўЮёЃЌетбљПЩвдБмУтЦфЫћвЕЮёгАЯьЁЃЙЋЙВМЏШКЛсДцЗХвЛаЉЩйСПЕФживЊвЕЮёКЭЗЧживЊЕФвЕЮёЁЃ ЗжИювЕЮёЃКЖдвЛаЉживЊвЕЮёгаБивЊзіЗжИюЃЌгІИУАбвЛаЉживЊвЕЮёЗжИюЕНВЛЭЌЕФNameSpaceжаЃЌетбљПЩвдБмУтЯрЛЅИЩШХЃЌЭЌЪБвВЪЧЖдвЕЮёЕФИєРыЁЃ зЪдДЗжХфЃКдкЕЅЕуЗўЮёВПЪ№ЪБашвЊзівЛаЉзЪдДЕФВржиКЭОљКтРћгУЁЃБШШчдкЭЌвЛИіНкЕуЩЯЭЌЪБгаZKЗўЮёЃЌNameNodeЗўЮёЃЌПЩФмУПИіЗўЮёЖМашвЊЖдGCзіЯргІЕФЩшжУЃЌетИіЪБКђЮвУЧашвЊзЈзЂЕБЧАМЏШКЕФетМИИіЗўЮёзДЬЌЃЌКЯРэХфжУЕБЧАгВМўЕФРћгУЁЃ NameSpaceЙмРэЃКЖдNameSpaceЙмРэЃЌетвЛЕуЪЧДгдЊЪ§ОнНЧЖШРДГіЗЂЃЌВЛНЈвщЙ§ДѓЃЌЙ§ДѓЛсгАЯьЯьгІЃЌЭЌЪБвВЛсгАЯьNameNodeДІРэЧыЧѓЃЌЪ§ОнСПДѓЕФЪБКђМгЩЯвЕЮёЧыЧѓвВБШНЯЖрЃЌПЩФмЛсГіЯжЖгСазшШћКЭЯьгІУЋДЬЕФЧщПіЁЃ RPCЗжМЖЙмРэЃКдЩњЕФRPCЪЧЩчЧјАцЕФЃЌЫћЪЧFIFOЕФДІРэЛњжЦЃЌдкКмЖрГЁОАЯТгаБивЊЖдRPCзіЗжМЖЙмРэЁЃЗжМЖЙмРэЕФЗНЪНгаКмЖржжЃЌБШШчЖгФкЗжМЖЃЌЛЙгаПЭЛЇЖЫЧыЧѓЕНNameNodeЕФбЙСІЖЏЬЌИажЊЕШЕШЁЃ ОљКтNameNodeЧыЧѓДІРэЃКNameNodeдкДІРэЧыЧѓвдМАЭЬЭТЗНУцгІИУгавЛИіОљКтЃЌвђЮЊдквЛИіNameNodeНкЕуЭЬЭТБШНЯИпЕФЧщПіЯТЃЌШчЙћДЫЪБNameNodeДІРэВЛМАЪБЃЌдкИпЗхЪБЖЮЛсГіЯжЗДгІЛиИДТ§ЕФЧщПіЁЃ Г§СЫетаЉвдЭташвЊжиЕуЙизЂЕФDataNodeКЭNameNodeЕФаФЬјЛњжЦЃЌвђЮЊDataNodeЪЧЪ§ОнадЕФЃЌЫћЕФДцЛюЖШЦфЪЕЗЧГЃживЊЁЃ 03 жиЕувЕЮёЗжЯэ ЖдгкММЪѕРДЫЕЃЌКУЕФММЪѕЭЈГЃЪЧРыВЛПЊецЪЕвЕЮёЕФбщжЄЕФЃЌЭјвздкДѓЪ§ОнЪЕМљгІгУГЁОАвВЪЧЗЧГЃЗсИЛКЭИДдгЕФЃЌЯТУцЗжЯэвЛИіЪЕМЪгІгУЙ§ГЬжаЕФГЁОАЁЃ
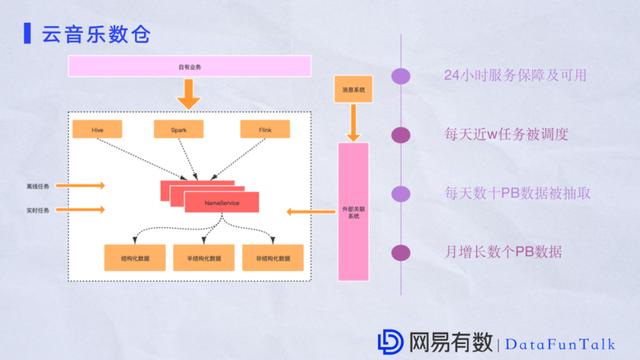
етЪЧФГИіВПУХЪ§ВжЕФвЕЮёЃЌЦфЪЕКмИДдгЁЃМЏШКжЇГжЖржжЪ§ОнИёЪНЃЌАыНсЙЙЛЏЪ§ОнКЭЗЧНсЙЙЛЏЪ§ОнЛсТНајСїШыЕНМЏШКжаЁЃЖјЧвгаДѓСПЕФРыЯпШЮЮёКЭЪЕЪБШЮЮёЁЃдкетИіЙ§ГЬУПЬьЛсгаЪ§ЪЎPBЕФЪ§ОнГіШЅЃЌдіГЄЫйТЪЗЧГЃПьЃЌзюживЊЕФЪЧетИіЙ§ГЬашвЊБЃеЯ24аЁЪБПЩгУЁЃЦфЪЕетИіЬєеНЯрЕБДѓЃЌОЙ§вЛЖЮЪБМфКЭвЕЮёЕФЙЕЭЈжЎКѓзіСЫКмЖргХЛЏЃЌФПЧАдЫааЗЧГЃСМКУЁЃ НёЬьЕФЗжЯэОЭЕНетРяЃЌаЛаЛДѓМвЁЃ
дкЮФФЉЗжЯэЁЂЕудоЁЂдкПДЃЌИјИі3СЌЛїпТ~
ЗжЯэМЮБіЃК

ЗжЯэМЮБіЃКзЃНЛЊ Эјвз зЪЩюДѓЪ§ОнЙЄГЬЪІ
БрМећРэЃКГТПЯш бЧЯУЙЩЗн ГіЦЗЦНЬЈЃКDataFunTalk
ЬэМгаЁжњЪжСДНгЃКhttps://wpz.h5.xeknow.com/s/3udZfR 1.УтЗбзЪСЯСьШЁЃКЕуЛїЩЯЗНСДНгЬэМгаЁжњЪжЛиИДЁОДѓЪ§ОнКЯМЏЁПУтЗбСьШЁЁЖДѓЪ§ОнЕфВиАцКЯМЏЁЗ ЛиИДЁОЫуЗЈКЯМЏЁПУтЗбСьШЁЁЖЛЅСЊЭјКЫаФЫуЗЈКЯМЏЁЗ 2.ЬэМгНЛСїШКЃКЕуЛїЕуЛїЩЯЗНСДНгЬэМгаЁжњЪжЛиИДЁОДѓЪ§ОнНЛСїШКЁПМгШыЁАДѓЪ§ОнНЛСїШКЁБ ЛиИДЁОЫуЗЈНЛСїШКЁПМгШыЁАЫуЗЈНЛСїШКЁБ | 









 - VIPЙКТђ - ЪжЛњАц - аЁКкЮн - еОЕуАяжњ - Л§ЗжЙцдђ - Л§ЗжГфжЕ - гАТЅБІ - ЙВЯэЕъЦЬ - ЦДЭХаЁГЬађ - АдЦСДѓЪІ - ЛюЖЏБІ - вўЫНУтд№ - ИќаТШежО - ЩчШКжБВЅ - ЩчШКЛњЦїШЫ - ЮЂИЛЭј
( ЖѕICPБИ2021020606КХ )
- VIPЙКТђ - ЪжЛњАц - аЁКкЮн - еОЕуАяжњ - Л§ЗжЙцдђ - Л§ЗжГфжЕ - гАТЅБІ - ЙВЯэЕъЦЬ - ЦДЭХаЁГЬађ - АдЦСДѓЪІ - ЛюЖЏБІ - вўЫНУтд№ - ИќаТШежО - ЩчШКжБВЅ - ЩчШКЛњЦїШЫ - ЮЂИЛЭј
( ЖѕICPБИ2021020606КХ )
зюаТЦРТл
ВщПДШЋВПЦРТл(3)