0x00.ЧАбджкЫљжмжЊЪ§ОнНсЙЙКЭЫуЗЈЪЧУцЪджиЕуЃЌЮвУЧГжајЗЂСІЪЧЪЎЗжУїжЧЕФЃЌвЊВЛШЛзюКѓПЯЖЈЪЧвЊГдПїЕФЃЌЩйДђДђгЮЯЗЫЂЫЂЮЂВЉПЩвдИФБфЮвУЧЕФЩњЛюЫЎЦНХЖЁЃ

ВЛЙ§БОЮФВЛЪЧвЊНВЪіЪ§ОнНсЙЙКЭЫуЗЈЕФЃЌЖјЪЧСэЭтвЛИіУцЪджиЕуRedisЃЌвђЮЊRedisвВЪЧПчгябдЕФЙВЭЌММЪѕЕуЃЌЮоТлЪЧJavaЛЙЪЧC++ЖМЛсЮЪЕНЃЌЫљвдЪЧИіИпЦЕУцЪдЕуЁЃ БЪепЪЧ2017ФъВХПЊЪМНгДЅRedisЕФЃЌЦкМфздМКДюЙ§ЕЅЛњАцКЭМЏШКАцЃЌВЛЙ§ЯждкЙЋЫОДѓвЛаЉЖМЭъШЋЪЧдЫЮЌРДЪЕЯжЕФЃЌЮвУЧЪЙгУепжЛашвЊдкwebвГУцНјааЯрЙиЩъЧыМДПЩЃЌКмЖрЯИНкЖМБЛЦСБЮСЫЃЌетбљЕБШЛКмЗНБуРВЃЌВЛЙ§ЮвУЧЛЙЪЧвЊЩюШыРэНтвЛЯТЕФЁЃ дкЙЄзїМИФъжаБЪепНгДЅЙ§RedisЁЂРрRedisЕФSSDBКЭPikaЁЂЙШИшЕФKey-ValueДцДЂв§ЧцLevelDBЁЂFackBookЕФKey-ValueДцДЂв§ЧцRocksDBЕШNoSQLЃЌЦфжаRedisЪЧЛљгкБъзМCгябдПЊЗЂЕФЃЌЪЧЙЄГЬжаКЭбЇЯАЩЯЖМЗЧГЃгХауЕФПЊдДЯюФПЁЃ жЎЧАБЪепаДЙ§МИЦЊзѓгвRedisЕФЮФеТЃЌЕЋЪЧжЊЪЖЕуЖМЗжЩЂзХВЛРћгкдФЖСЃЌЫљвдБОДЮОЭАбжЎЧАЕФЮФеТНјааЛузмВЙГфЃЌРДаЮГЩвЛИіШЋвЛаЉЕФМЏКЯЃЌЯЃЭћЖдЙизЂЮвЕФЖСепгаЫљАяжњОЭзуЙЛРВЁЃ ЮФжаСаГіРДЕФПМЕуНЯЖрВЂЧвРлМЦДя3w+зж ЃЌвђДЫНЈвщЖСепЪеВиЃЌвдБИВЛЪБжЎашЃЌЭЈЙ§БОЮФФуНЋСЫНтЕНвдЯТФкШнЃК - RedisЕФзїепКЭЗЂеЙМђЪЗ
- RedisГЃгУЪ§ОнНсЙЙМАЦфЪЕЯж
- RedisЕФSDSКЭCжазжЗћДЎЕФдРэКЭЖдБШ
- RedisгаађМЏКЯZSetЕФЕзВуЩшМЦКЭЪЕЯж
- RedisгаађМЏКЯZSetКЭЬјдОСДБэЮЪЬт
- RedisзжЕфЕФЪЕЯжМАНЅНјЪНRehashЙ§ГЬ
- RedisЕЅЯпГЬдЫааФЃЪНЕФЛљБОдРэКЭСїГЬ
- RedisЗДгІЖбФЃЪНЕФдРэКЭЩшМЦЪЕЯж
- RedisГжОУЛЏЗНАИМАЦфЛљБОдРэ
- МЏШКАцRedisКЭGossipавщ
- RedisФкДцЛиЪеЛњжЦКЭЛљБОдРэ
- RedisЪ§ОнЭЌВНЛњжЦКЭЛљБОдРэ
ЛАВЛЖрЫЕЃЌЪБЫй400ЙЋРяЕФДѓАзКХ ПЊЪММгЫйЃЁ

БЪепОЁСПЯъЯИЕиВћЪіУПИіЮЪЬтЃЌжМдкЩюШыРэНтБмУтрёр№ЭЬдцЕФБГЫаЃЌЕБШЛвВЛсДцдквЛаЉВЛзуЃЌШчгаЮЪЬтПЩЫНаХЮвЁЃ 0x01. ЪВУДЪЧRedisМАЦфживЊадЃПRedisЪЧвЛИіЪЙгУANSI CБраДЕФПЊдДЁЂжЇГжЭјТчЁЂЛљгкФкДцЁЂПЩбЁГжОУЛЏЕФИпадФмМќжЕЖдЪ§ОнПтЁЃ RedisЕФжЎИИЪЧРДздвтДѓРћЕФЮїЮїРяЕКЕФSalvatore SanfilippoЃЌGithubЭјУћantirezЃЌБЪепевСЫзїепЕФвЛаЉМђвЊаХЯЂВЂЗвыСЫвЛЯТЃЌШчЭМЃК
Дг2009ФъЕквЛИіАцБОЦ№RedisвбОзпЙ§СЫ10ИіФъЭЗЃЌФПЧАRedisвРОЩЪЧзюСїааЕФkey-valueаЭФкДцЪ§ОнПтЕФжЎвЛЁЃ гХауЕФПЊдДЯюФПРыВЛПЊДѓЙЋЫОЕФжЇГжЃЌдк2013Фъ5дТжЎЧАЃЌЦфПЊЗЂгЩVMwareдожњЃЌЖј2013Фъ5дТжС2015Фъ6дТЦкМфЃЌЦфПЊЗЂгЩБЯЭўЭидожњЃЌДг2015Фъ6дТПЊЪМЃЌRedisЕФПЊЗЂгЩRedis LabsдожњЁЃ

БЪепвВЪЙгУЙ§вЛаЉЦфЫћЕФNoSQLЃЌгаЕФжЇГжЕФvalueРраЭЗЧГЃЕЅвЛЃЌвђДЫКмЖрВйзїЖМБиаыдкПЭЛЇЖЫЪЕЯжЃЌБШШчvalueЪЧвЛИіНсЙЙЛЏЕФЪ§ОнЃЌашвЊаоИФЦфжаФГИізжЖЮОЭашвЊећЬхЖСГіРДаоИФдйећЬхаДШыЃЌЯдЕУКмБПжиЃЌЕЋЪЧRedisЕФvalueжЇГжЖржжРраЭЃЌЪЕЯжСЫКмЖрВйзїдкЗўЮёЖЫОЭПЩвдЭъГЩСЫЃЌетИіЖдПЭЛЇЖЫЖјбдЗЧГЃЗНБуЁЃ ЕБШЛRedisгЩгкЪЧФкДцаЭЕФЪ§ОнПтЃЌЪ§ОнСПДцДЂСПгаЯоЖјЧвЗжВМЪНМЏШКГЩБОвВЛсЗЧГЃИпЃЌвђДЫгаКмЖрЙЋЫОПЊЗЂСЫЛљгкSSDЕФРрRedisЯЕЭГЃЌБШШч360ПЊЗЂЕФSSDBЁЂPikaЕШЪ§ОнПтЃЌЕЋЪЧБЪепШЯЮЊДг0ЕН1ЕФФбЖШЪЧДѓгкДг1ЕН2ЕФФбЖШЕФЃЌЮугЙжУвЩRedisЪЧNoSQLжаХЈФЋжиВЪЕФвЛБЪЃЌжЕЕУЮвУЧШЅЩюШыбаОПКЭЪЙгУЁЃ RedisЬсЙЉСЫJavaЁЂC/C++ЁЂC#ЁЂ PHP ЁЂJavaScriptЁЂ Perl ЁЂObject-CЁЂPythonЁЂRubyЁЂErlangЁЂGolangЕШЖржжжїСїгябдЕФПЭЛЇЖЫЃЌвђДЫЮоТлЪЙгУепЪЧЪВУДгябдеЛзмЛсевЕНЪєгкздМКЕФФЧПюПЭЛЇЖЫЃЌЪмжкЗЧГЃЙуЁЃ БЪепВщСЫdatanyze.comЭјеОПДСЫЯТRedisКЭMySQLЕФзюаТЪаГЁЗнЖюКЭХХУћЖдБШвдМАШЋЧђTopеОЕуЕФВПЪ№СПЖдБШ(ЭјеОЪ§Он2019.12)ЃК
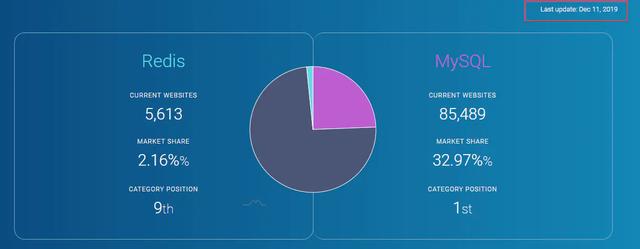
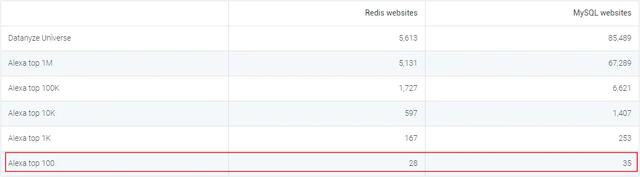
ПЩвдПДЕНRedisзмЬхЗнЖюХХУћЕк9ВЂЧвдкШЋЧђTop100еОЕужаВПЪ№Ъ§СПгыMySQLЛљБОГжЦНЃЌЫљвдRedisЛЙЪЧгавЛЖЈЕФНКўЕиЮЛЕФЁЃ 0x02. МђЪіRedisГЃгУЕФЪ§ОнНсЙЙМАЦфШчКЮЪЕЯжЕФЃПRedisжЇГжЕФГЃгУ5жжЪ§ОнРраЭжИЕФЪЧvalueРраЭЃЌЗжБ№ЮЊЃКзжЗћДЎStringЁЂСаБэListЁЂЙўЯЃHashЁЂМЏКЯSetЁЂгаађМЏКЯZsetЃЌЕЋЪЧRedisКѓајгжЗсИЛСЫМИжжЪ§ОнРраЭЗжБ№ЪЧBitmapsЁЂHyperLogLogsЁЂGEOЁЃ гЩгкRedisЪЧЛљгкБъзМCаДЕФЃЌжЛгазюЛљДЁЕФЪ§ОнРраЭЃЌвђДЫRedisЮЊСЫТњзуЖдЭтЪЙгУЕФ5жжЪ§ОнРраЭЃЌПЊЗЂСЫЪєгкздМКЖРгаЕФвЛЬзЛљДЁЪ§ОнНсЙЙЃЌЪЙгУетаЉЪ§ОнНсЙЙРДЪЕЯж5жжЪ§ОнРраЭЁЃ RedisЕзВуЕФЪ§ОнНсЙЙАќРЈЃКМђЕЅЖЏЬЌЪ§зщSDSЁЂСДБэЁЂзжЕфЁЂЬјдОСДБэЁЂећЪ§МЏКЯЁЂбЙЫѕСаБэЁЂЖдЯѓЁЃ RedisЮЊСЫЦНКтПеМфКЭЪБМфаЇТЪЃЌеыЖдvalueЕФОпЬхРраЭдкЕзВуЛсВЩгУВЛЭЌЕФЪ§ОнНсЙЙРДЪЕЯжЃЌЦфжаЙўЯЃБэКЭбЙЫѕСаБэЪЧИДгУБШНЯЖрЕФЪ§ОнНсЙЙЃЌШчЯТЭМеЙЪОСЫЖдЭтЪ§ОнРраЭКЭЕзВуЪ§ОнНсЙЙжЎМфЕФгГЩфЙиЯЕЃК
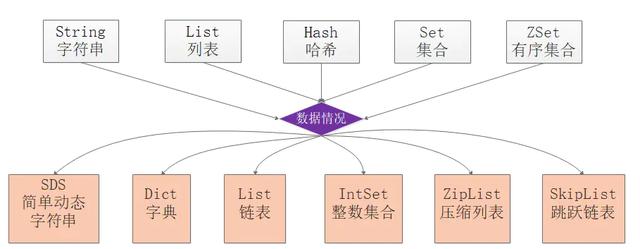
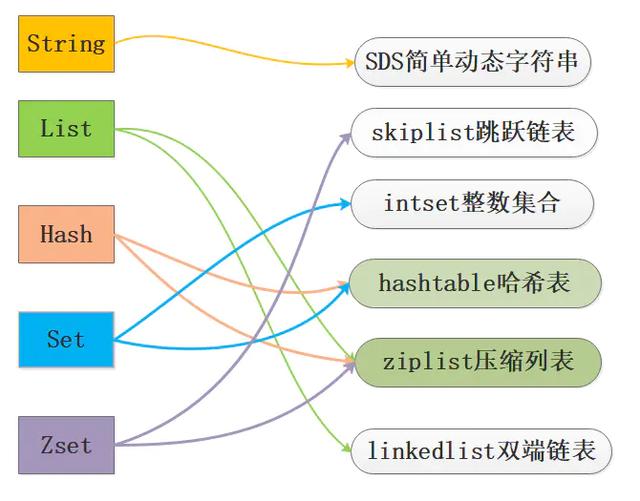
ДгЭМжаПЩвдПДЕНziplistбЙЫѕСаБэПЩвдзїЮЊZsetЁЂSetЁЂListШ§жжЪ§ОнРраЭЕФЕзВуЪЕЯжЃЌПДРДКмЧПДѓЃЌбЙЫѕСаБэЪЧвЛжжЮЊСЫНкдМФкДцЖјПЊЗЂЕФЧвОЙ§ЬиЪтБрТыжЎКѓЕФСЌајФкДцПщЫГађаЭЪ§ОнНсЙЙЃЌЕзВуНсЙЙЛЙЪЧБШНЯИДдгЕФЁЃ 0x03. RedisЕФSDSКЭCжазжЗћДЎЯрБШгаЪВУДгХЪЦЃПдкCгябджаЪЙгУN+1ГЄЖШЕФзжЗћЪ§зщРДБэЪОзжЗћДЎЃЌЮВВПЪЙгУ'\0'зїЮЊНсЮВБъжОЃЌЖдгкДЫжжЪЕЯжЮоЗЈТњзуRedisЖдгкАВШЋадЁЂаЇТЪЁЂЗсИЛЕФЙІФмЕФвЊЧѓЃЌвђДЫRedisЕЅЖРЗтзАСЫSDSМђЕЅЖЏЬЌзжЗћДЎНсЙЙЁЃ дкРэНтSDSЕФгХЪЦжЎЧАашвЊЯШПДЯТSDSЕФЪЕЯжЯИНкЃЌевСЫgithubзюаТЕФsrc/sds.hЕФЖЈвхПДЯТЃК typedef char *sds;/*етИігУВЛЕН КіТдМДПЩ*/struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[];};/*ВЛЭЌГЄЖШЕФheader 8 16 32 64ЙВ4жж ЖМИјГіСЫЫФИіГЩдБlenЃКЕБЧАЪЙгУЕФПеМфДѓаЁЃЛallocШЅЕєheaderКЭНсЮВПезжЗћЕФзюДѓПеМфДѓаЁflags:8ЮЛЕФБъМЧ ЯТУцЙигкSDS_TYPE_xЕФКъЖЈвхжЛга5жж 3bitзуЙЛСЫ 5bitУЛгагУbuf:етИіИњCгябджаЕФзжЗћЪ§зщЪЧвЛбљЕФЃЌДгtypedef char* sdsПЩвджЊЕРОЭЪЧетбљЕФЁЃbufЕФзюДѓГЄЖШЪЧ2^n ЦфжаnЮЊsdshdrЕФРраЭЃЌШчЕБбЁдёsdshdr16ЃЌbuf_max=2^16ЁЃ*/struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};#define SDS_TYPE_5 0#define SDS_TYPE_8 1#define SDS_TYPE_16 2#define SDS_TYPE_32 3#define SDS_TYPE_64 4#define SDS_TYPE_MASK 7#define SDS_TYPE_BITS 3
ПДСЫЧАУцЕФЖЈвхЃЌБЪепЛСЫИіЭМЃК
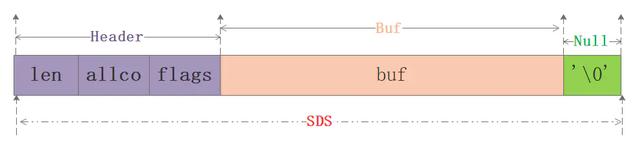
ДгЭМжаПЩвджЊЕРsdsБОжЪЗжЮЊШ§ВПЗжЃКheaderЁЂbufЁЂnullНсЮВЗћЃЌЦфжаheaderПЩвдШЯЮЊЪЧећИіsdsЕФжИв§ВПЗжЃЌИјЖЈСЫЪЙгУЕФПеМфДѓаЁЁЂзюДѓЗжХфДѓаЁЕШаХЯЂЃЌдйгУвЛеХЭјЩЯЕФЭМРДЧхЮњПДЯТsdshdr8ЕФЪЕР§ЃК
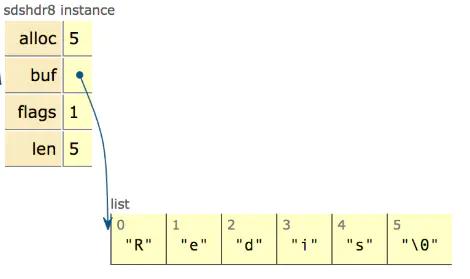
дкsds.h/sds.cдДТыжаПЩЧхГўЕиПДЕНsdsЭъећЕФЪЕЯжЯИНкЃЌБОЮФОЭВЛеЙПЊСЫвЊВЛШЛЦЊЗљОЭЙ§ГЄСЫЃЌПьЫйНјШыжїЬтЫЕЯТsdsЕФгХЪЦЃК - O(1)ЛёШЁГЄЖШ: CзжЗћДЎашвЊБщРњЖјsdsжагаlenПЩвджБНгЛёЕУЃЛ
- ЗРжЙЛКГхЧјвчГіbufferoverflow: ЕБsdsашвЊЖдзжЗћДЎНјаааоИФЪБЃЌЪзЯШНшжњгкlenКЭallocМьВщПеМфЪЧЗёТњзуаоИФЫљашЕФвЊЧѓЃЌШчЙћПеМфВЛЙЛЕФЛАЃЌSDSЛсздЖЏРЉеЙПеМфЃЌБмУтСЫЯёCзжЗћДЎВйзїжаЕФИВИЧЧщПіЃЛ
- гааЇНЕЕЭФкДцЗжХфДЮЪ§ЃКCзжЗћДЎдкЩцМАдіМгЛђепЧхГ§ВйзїЪБЛсИФБфЕзВуЪ§зщЕФДѓаЁдьГЩжиаТЗжХфЁЂsdsЪЙгУСЫПеМфдЄЗжХфКЭЖшадПеМфЪЭЗХЛњжЦЃЌЫЕАзСЫОЭЪЧУПДЮдкРЉеЙЪБЪЧГЩБЖЕФЖрЗжХфЕФЃЌдкЫѕШнЪЧвВЪЧЯШСєзХВЂВЛе§ЪНЙщЛЙИјOSЃЌетСНИіЛњжЦвВЪЧБШНЯКУРэНтЕФЃЛ
- ЖўНјжЦАВШЋЃКCгябдзжЗћДЎжЛФмБЃДцasciiТыЃЌЖдгкЭМЦЌЁЂвєЦЕЕШаХЯЂЮоЗЈБЃДцЃЌsdsЪЧЖўНјжЦАВШЋЕФЃЌаДШыЪВУДЖСШЁОЭЪЧЪВУДЃЌВЛзіШЮКЮЙ§ТЫКЭЯожЦЃЛ
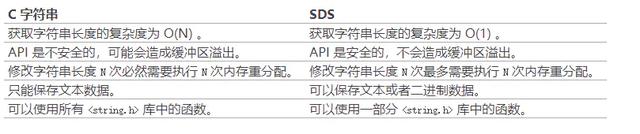
РЯЙцОиЩЯвЛеХЛЦНЁКъДѓЩёзмНсКУЕФЭМЃК
0x04. RedisЕФзжЕфЪЧШчКЮЪЕЯжЕФЃПМђЪіНЅНјЪНrehashЙ§ГЬзжЕфЫуЪЧRedisжаГЃгУЪ§ОнРраЭжаЕФУїаЧГЩдБСЫЃЌЧАУцЫЕЙ§зжЕфПЩвдЛљгкziplistКЭhashtableРДЪЕЯжЃЌЮвУЧжЛЬжТлЛљгкhashtableЪЕЯжЕФдРэЁЃ зжЕфЪЧИіВуДЮЗЧГЃУїЯдЕФЪ§ОнРраЭЃЌШчЭМЃК
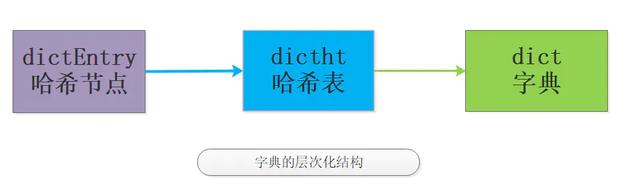
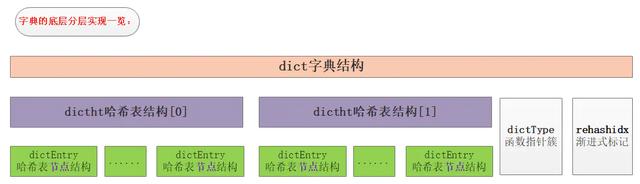
гаСЫИіДѓИХЕФИХФюЃЌЮвУЧПДЯТзюаТЕФsrc/dict.hдДТыЖЈвхЃК //ЙўЯЃНкЕуНсЙЙtypedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next;} dictEntry;//ЗтзАЕФЪЧзжЕфЕФВйзїКЏЪ§жИеыtypedef struct dictType { uint64_t (*hashFunction)(const void *key); void *(*keyDup)(void *privdata, const void *key); void *(*valDup)(void *privdata, const void *obj); int (*keyCompare)(void *privdata, const void *key1, const void *key2); void (*keyDestructor)(void *privdata, void *key); void (*valDestructor)(void *privdata, void *obj);} dictType;/* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. *///ЙўЯЃБэНсЙЙ ИУВПЗжЪЧРэНтзжЕфЕФЙиМќtypedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used;} dictht;//зжЕфНсЙЙtypedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */} dict;
CгябдЕФКУДІдкгкЖЈвхБиаыЪЧгЩзюЕзВуЯђЭтЕФЃЌвђДЫЮвУЧПЩвдПДЕНвЛИіУїЯдЕФВуДЮБфЛЏЃЌгкЪЧБЪепгжЛвЛЭМРДеЙЯжОпЬхЕФВуДЮИХФюЃК
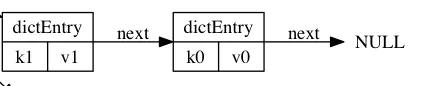
dictEntryЪЧЙўЯЃБэНкЕуЃЌвВОЭЪЧЮвУЧДцДЂЪ§ОнЕиЗНЃЌЦфБЃЛЄЕФГЩдБгаЃКkey,v,nextжИеыЁЃkeyБЃДцзХМќжЕЖджаЕФМќЃЌvБЃДцзХМќжЕЖджаЕФжЕЃЌжЕПЩвдЪЧвЛИіжИеыЛђепЪЧuint64_tЛђепЪЧint64_tЁЃnextЪЧжИЯђСэвЛИіЙўЯЃБэНкЕуЕФжИеыЃЌетИіжИеыПЩвдНЋЖрИіЙўЯЃжЕЯрЭЌЕФМќжЕЖдСЌНгдквЛДЮЃЌвдДЫРДНтОіЙўЯЃГхЭЛЕФЮЪЬтЁЃ ШчЭМЮЊСНИіГхЭЛЕФЙўЯЃНкЕуЕФСЌНгЙиЯЕЃК
ДгдДТыПДЙўЯЃБэАќРЈЕФГЩдБгаtableЁЂsizeЁЂusedЁЂsizemaskЁЃtableЪЧвЛИіЪ§зщЃЌЪ§зщжаЕФУПИідЊЫиЖМЪЧвЛИіжИЯђdictEntryНсЙЙЕФжИеыЃЌ УПИіdictEntryНсЙЙБЃДцзХвЛИіМќжЕЖдЃЛsize ЪєадМЧТМСЫЙўЯЃБэtableЕФДѓаЁЃЌЖјusedЪєаддђМЧТМСЫЙўЯЃБэФПЧАвбгаНкЕуЕФЪ§СПЁЃsizemaskЕШгкsize-1КЭЙўЯЃжЕМЦЫувЛИіМќдкtableЪ§зщЕФЫїв§ЃЌвВОЭЪЧМЦЫуindexЪБгУЕНЕФЁЃ
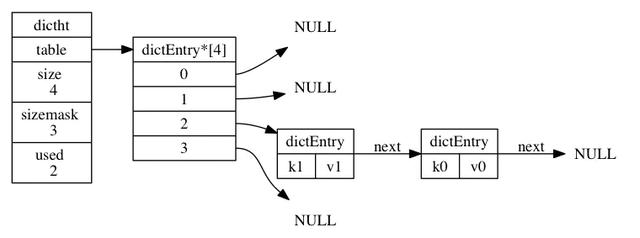
ШчЩЯЭМеЙЪОСЫвЛИіДѓаЁЮЊ4ЕФtableжаЕФЙўЯЃНкЕуЧщПіЃЌЦфжаk1КЭk0дкindex=2ЗЂЩњСЫЙўЯЃГхЭЛЃЌНјааПЊСДБэДцдкЃЌБОжЪЩЯЪЧЯШДцДЂЕФk0ЃЌk1ЗХжУЪЧЗЂЩњГхЭЛЮЊСЫБЃжЄаЇТЪжБНгЗХдкГхЭЛСДБэЕФзюЧАУцЃЌвђЮЊИУСДБэУЛгаЮВжИеыЁЃ ДгдДТыжаПДЕНdictНсЙЙЬхОЭЪЧзжЕфЕФЖЈвхЃЌАќКЌЕФГЩдБгаtypeЃЌprivdataЁЂhtЁЂrehashidxЁЃЦфжаdictTypeжИеыРраЭЕФtypeжИЯђСЫВйзїзжЕфЕФapiЃЌРэНтЮЊКЏЪ§жИеыМДПЩЃЌhtЪЧАќКЌ2ИіdicthtЕФЪ§зщЃЌвВОЭЪЧзжЕфАќКЌСЫ2ИіЙўЯЃБэЃЌrehashidxНјааrehashЪБЪЙгУЕФБфСПЃЌprivdataХфКЯdictTypeжИЯђЕФКЏЪ§зїЮЊВЮЪ§ЪЙгУЃЌетбљОЭЖдзжЕфЕФМИИіГЩдБгаСЫГѕВНЕФШЯЪЖЁЃ
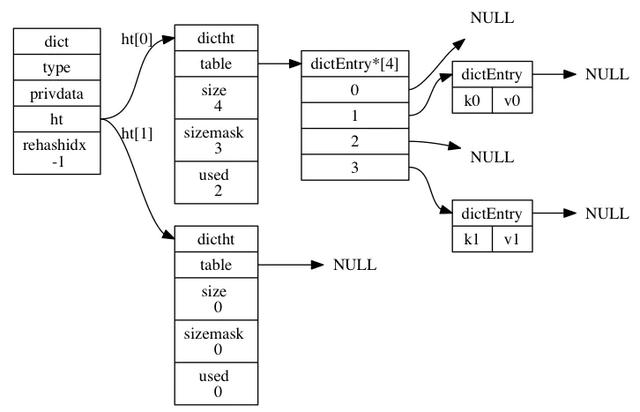
зжЕфЕФЙўЯЃЫуЗЈ //ЮБТыЃКЪЙгУЙўЯЃКЏЪ§ЃЌМЦЫуМќkeyЕФЙўЯЃжЕhash = dict->type->hashFunction(key);//ЮБТыЃКЪЙгУЙўЯЃБэЕФsizemaskКЭЙўЯЃжЕЃЌМЦЫуГідкht[0]Лђаэht[1]ЕФЫїв§жЕindex = hash & dict->ht[x].sizemask;//дДТыЖЈвх#define dictHashKey(d, key) (d)->type->hashFunction(key)
redisЪЙгУMurmurHashЫуЗЈМЦЫуЙўЯЃжЕЃЌИУЫуЗЈзюГѕгЩAustin Applebyдк2008ФъЗЂУїЃЌMurmurHashЫуЗЈЕФЮоТлЪ§ОнЪфШыЧщПіШчКЮЖМПЩвдИјГіЫцЛњЗжВМадНЯКУЕФЙўЯЃжЕВЂЧвМЦЫуЫйЖШЗЧГЃПьЃЌФПЧАгаMurmurHash2КЭMurmurHash3ЕШАцБОЁЃ ЙўЯЃБэБЃДцЕФМќжЕЖдЪ§СПЪЧЖЏЬЌБфЛЏЕФЃЌЮЊСЫШУЙўЯЃБэЕФИКдивђзгЮЌГждквЛИіКЯРэЕФЗЖЮЇжЎФкЃЌОЭашвЊЖдЙўЯЃБэНјааРЉЫѕШнЁЃ РЉЫѕШнЪЧЭЈЙ§жДааrehashжиаТЩЂСаРДЭъГЩЃЌЖдзжЕфЕФЙўЯЃБэжДааЦеЭЈrehashЕФЛљБОВНжшЮЊЗжХфПеМф->ж№ИіЧЈвЦ->НЛЛЛЙўЯЃБэЃЌЯъЯИЙ§ГЬШчЯТЃК - ЮЊзжЕфЕФht[1]ЙўЯЃБэЗжХфПеМфЃЌЗжХфЕФПеМфДѓаЁШЁОігквЊжДааЕФВйзївдМАht[0]ЕБЧААќКЌЕФМќжЕЖдЪ§СПЃК
РЉеЙВйзїЪБht[1]ЕФДѓаЁЮЊЕквЛИіДѓгкЕШгкht[0].used*2ЕФ2^nЃЛ
ЪеЫѕВйзїЪБht[1]ЕФДѓаЁЮЊЕквЛИіДѓгкЕШгкht[0].usedЕФ2^n ЃЛРЉеЙЪББШШчh[0].used=200ЃЌФЧУДашвЊбЁдёДѓгк400ЕФЕквЛИі2ЕФУнЃЌвВОЭЪЧ2^9=512ЁЃ - НЋБЃДцдкht[0]жаЕФЫљгаМќжЕЖджиаТМЦЫуМќЕФЙўЯЃжЕКЭЫїв§жЕrehashЕНht[1]ЩЯЃЛ
- жиИДrehashжБЕНht[0]АќКЌЕФЫљгаМќжЕЖдШЋВПЧЈвЦЕНСЫht[1]жЎКѓЪЭЗХ ht[0]ЃЌ НЋht[1]ЩшжУЮЊ ht[0]ЃЌВЂдкht[1]аТДДНЈвЛИіПеАзЙўЯЃБэЃЌ ЮЊЯТвЛДЮrehashзізМБИЁЃ
RedisЕФrehashЖЏзїВЂВЛЪЧвЛДЮадЭъГЩЕФЃЌЖјЪЧЗжЖрДЮЁЂНЅНјЪНЕиЭъГЩЕФЃЌдвђдкгкЕБЙўЯЃБэРяБЃДцЕФМќжЕЖдЪ§СПКмДѓЪБЃЌ вЛДЮадНЋетаЉМќжЕЖдШЋВПrehashЕНht[1]ПЩФмЛсЕМжТЗўЮёЦїдквЛЖЮЪБМфФкЭЃжЙЗўЮёЃЌетИіЪЧЮоЗЈНгЪмЕФЁЃ еыЖдетжжЧщПіRedisВЩгУСЫНЅНјЪНrehashЃЌЙ§ГЬЕФЯъЯИВНжшЃК - ЮЊht[1]ЗжХфПеМфЃЌетИіЙ§ГЬКЭЦеЭЈRehashУЛгаЧјБ№ЃЛ
- НЋrehashidxЩшжУЮЊ0ЃЌБэЪОrehashЙЄзїе§ЪНПЊЪМЃЌЭЌЪБетИіrehashidxЪЧЕндіЕФЃЌДг0ПЊЪМБэЪОДгЪ§зщЕквЛИідЊЫиПЊЪМrehashЁЃ
- дкrehashНјааЦкМфЃЌУПДЮЖдзжЕфжДаадіЩОИФВщВйзїЪБЃЌЫГДјНЋht[0]ЙўЯЃБэдкrehashidxЫїв§ЩЯЕФМќжЕЖдrehashЕН ht[1]ЃЌЭъГЩКѓНЋrehashidxМг1ЃЌжИЯђЯТвЛИіашвЊrehashЕФМќжЕЖдЁЃ
- ЫцзХзжЕфВйзїЕФВЛЖЯжДааЃЌзюжеht[0]ЕФЫљгаМќжЕЖдЖМЛсБЛrehashжСht[1]ЃЌдйНЋrehashidxЪєадЕФжЕЩшЮЊ-1РДБэЪО rehashВйзївбЭъГЩЁЃ
НЅНјЪН rehashЕФЫМЯыдкгкНЋrehashМќжЕЖдЫљашЕФМЦЫуЙЄзїЗжЩЂЕНЖдзжЕфЕФУПИіЬэМгЁЂЩОГ§ЁЂВщевКЭИќаТВйзїЩЯЃЌДгЖјБмУтСЫМЏжаЪНrehashЖјДјРДЕФзшШћЮЪЬтЁЃ ПДЕНетРяВЛНћШЅЯыетжжЩгДјНХЪНЕФrehashЛсВЛЛсЕМжТећИіЙ§ГЬЗЧГЃТўГЄЃПШчЙћФГИіvalueвЛжБУЛгаВйзїФЧУДашвЊРЉШнЪБгЩгквЛжБВЛгУЫљвдгАЯьВЛДѓЃЌашвЊЫѕШнЪБШчЙћвЛжБВЛДІРэПЩФмдьГЩФкДцРЫЗбЃЌОпЬхЕФЛЙУЛРДЕУМАбаОПЃЌЯШТёИіЮЪЬтАЩЃЁ 0x05. НВНВ4.0жЎЧААцБОЕФRedisЕФЕЅЯпГЬдЫааФЃЪНБОжЪЩЯRedisВЂВЛЪЧЕЅДПЕФЕЅЯпГЬЗўЮёФЃаЭЃЌвЛаЉИЈжњЙЄзїБШШчГжОУЛЏЫЂХЬЁЂЖшадЩОГ§ЕШШЮЮёЪЧгЩBIOЯпГЬРДЭъГЩЕФЃЌетРяЫЕЕФЕЅЯпГЬжївЊЪЧЫЕгыПЭЛЇЖЫНЛЛЅЭъГЩУќСюЧыЧѓКЭЛиИДЕФЙЄзїЯпГЬЁЃ жСгкAntirezДѓРаЕБЪБЪЧдѕУДЯыЕФЩшМЦЮЊЕЅЯпГЬВЛЕУЖјжЊЃЌжЛФмДгМИИіНЧЖШРДЗжЮіЃЌРДШЗЖЈЕЅЯпГЬФЃаЭЕФбЁдёдвђЁЃ 5.1 ЕЅЯпГЬФЃЪНЕФПМСПCPUВЂЗЧЦПОБЃКЖрЯпГЬФЃаЭжївЊЪЧЮЊСЫГфЗжРћгУЖрКЫCPUЃЌШУЯпГЬдкIOзшШћЪББЛЙвЦ№ШУГіCPUЪЙгУШЈНЛИјЦфЫћЯпГЬЃЌГфЗжЬсИпCPUЕФЪЙгУТЪЃЌЕЋЪЧетИіГЁОАдкRedisВЂВЛУїЯдЃЌвђЮЊCPUВЂВЛЪЧRedisЕФЦПОБЃЌRedisЕФЫљгаВйзїЖМЪЧЛљгкФкДцЕФЃЌДІРэЪТМўМЋПьЃЌвђДЫЪЙгУЖрЯпГЬРДЧаЛЛЯпГЬЬсИпCPUРћгУТЪЕФашЧѓВЂВЛЧПСвЃЛ ФкДцВХЪЧЦПОБЃКЕЅИіRedisЪЕР§ЖдЕЅКЫЕФРћгУвбОКмКУСЫЃЌЕЋЪЧRedisЕФЦПОБдкгкФкДцЃЌЩшЯы64КЫЕФЛњЦїМйШчФкДцжЛга16GBЃЌФЧУДЖрЯпГЬRedisгаЪВУДгУЮфжЎЕиЃП ИДдгЕФValueРраЭЃКRedisгаЗсИЛЕФЪ§ОнНсЙЙЃЌВЂВЛЪЧМђЕЅЕФKey-ValueаЭЕФNoSQLЃЌетвВЪЧRedisБИЪмЛЖгЕФдвђЃЌЦфжаГЃгУЕФHashЁЂZsetЁЂListЕШНсЙЙдкvalueКмДѓЪБЃЌCURDЕФВйзїЛсКмИДдгЃЌШчЙћВЩгУЖрЯпГЬФЃЪНдкНјааЯрЭЌkeyВйзїЪБОЭашвЊМгЫјРДНјааЭЌВНЃЌетбљОЭПЩФмдьГЩЫРЫјЮЪЬтЁЃ етЪБКђФуЛсЮЪЃКНЋkeyзіhashЗжХфИјЯрЭЌЕФЯпГЬРДДІРэОЭПЩвдНтОібНЃЌШЗЪЕЪЧетбљЕФЃЌетбљЕФЛАОЭашвЊдкRedisжадіМгkeyЕФhashДІРэвдМАЖрЯпГЬИКдиОљКтЕФДІРэЃЌДгЖјRedisЕФЪЕЯжОЭГЩЮЊЖрЯпГЬФЃЪНСЫЃЌКУЯёШЗЪЕвВУЛгаЪВУДЮЪЬтЃЌЕЋЪЧAntirezВЂУЛгаетУДзіЃЌДѓЩёетУДзіПЯЖЈЪЧгадвђЕФЃЌЙћВЛЦфШЛЃЌЮвУЧМћЕНСЫМЏШКЛЏЕФRedisЃЛ МЏШКЛЏРЉеЙЃКФПЧАЕФЛњЦїЖМЪЧЖрКЫЕФЃЌЕЋЪЧФкДцвЛАу128GB/64GBЫуЪЧБШНЯЦеБщСЫЃЌЕЋЪЧRedisдкЪЙгУФкДц60%вдЩЯЮШЖЈадОЭВЛШч50%ЕФадФмСЫ(жСЩйБЪепдкЪЙгУМЏШКЛЏRedisЪБГЌЙ§70%ЪБЃЌМЏШКfailoverЕФЦЕТЪЛсИќИп)ЃЌвђДЫдкЪ§ОнНЯДѓЪБЃЌЕБRedisзїЮЊжїДцЃЌОЭБиаыЪЙгУЖрЬЈЛњЦїЙЙНЈМЏШКЛЏЕФRedisЪ§ОнПтЯЕЭГЃЌетбљвдРДRedisЕФЕЅЯпГЬФЃЪНгжБЛМЏШКЛЏЕФДІРэЫљРЉеЙСЫЃЛ ШэМўЙЄГЬНЧЖШЃКЕЅЯпГЬЮоТлДгПЊЗЂКЭЮЌЛЄЖМБШЖрЯпГЬвЊШнвзЗЧГЃЖрЃЌВЂЧввВФмЬсИпЗўЮёЕФЮШЖЈадЃЌЮоЫјЛЏДІРэШУЕЅЯпГЬЕФRedisдкПЊЗЂКЭЮЌЛЄЩЯЖМОпБИЯрЕБДѓЕФгХЪЦЃЛ РрRedisЯЕЭГЃКRedisЕФЩшМЦБќГаЪЕгУЕквЛКЭЙЄГЬЛЏЃЌЫфШЛгаКмЖрРэТлЩЯгХауЕФЩшМЦФЃЪНЃЌЕЋЪЧВЂВЛвЛЖЈЪЪгУздМКЃЌШэМўЩшМЦЙ§ГЬОЭЪЧШЈКтЕФЙ§ГЬЁЃвЕФквВгааэЖрРрRedisЕФNoSQLЃЌБШШч360ЛљДЁМмЙЙзщПЊЗЂЕФPikaЯЕЭГЃЌЛљгкSSDКЭRocksДцДЂв§ЧцЃЌЩЯВуЗтзАвЛВуавщзЊЛЛЃЌРДЪЕЯжRedisЫљгаЙІФмЕФФЃФтЃЌИааЫШЄЕФПЩвдбаОПКЭЪЙгУЁЃ 5.2 RedisЕФЮФМўЪТМўКЭЪБМфЪТМўRedisзїЮЊЕЅЯпГЬЗўЮёвЊДІРэЕФЙЄзївЛЕувВВЛЩйЃЌRedisЪЧЪТМўЧ§ЖЏЕФЗўЮёЦїЃЌжївЊЕФЪТМўРраЭОЭЪЧЃКЮФМўЪТМўРраЭКЭЪБМфЪТМўРраЭЃЌЦфжаЪБМфЪТМўЪЧРэНтЕЅЯпГЬТпМФЃаЭЕФЙиМќЁЃ RedisЕФЪБМфЪТМўЗжЮЊСНРрЃК - ЖЈЪБЪТМўЃКШЮЮёдкЕШД§жИЖЈДѓаЁЕФЕШД§ЪБМфжЎКѓОЭжДааЃЌжДааЭъГЩОЭВЛдйжДааЃЌжЛДЅЗЂвЛДЮЃЛ
- жмЦкЪТМўЃКШЮЮёУПИєвЛЖЈЪБМфОЭжДааЃЌжДааЭъГЩжЎКѓЕШД§ЯТвЛДЮжДааЃЌЛсжмЦкадЕФДЅЗЂЃЛ
RedisжаДѓВПЗжЪЧжмЦкЪТМўЃЌжмЦкЪТМўжївЊЪЧЗўЮёЦїЖЈЦкЖдздЩэдЫааЧщПіНјааМьВтКЭЕїећЃЌДгЖјБЃжЄЮШЖЈадЃЌетЯюЙЄзїжївЊЪЧServerCronКЏЪ§РДЭъГЩЕФЃЌжмЦкЪТМўЕФФкШнжївЊАќРЈЃК - ЩОГ§Ъ§ОнПтЕФkey
- ДЅЗЂRDBКЭAOFГжОУЛЏ
- жїДгЭЌВН
- МЏШКЛЏБЃЛЄ
- ЙиБеЧхРэЫРПЭЛЇЖЫСДНг
- ЭГМЦИќаТЗўЮёЦїЕФФкДцЁЂkeyЪ§СПЕШаХЯЂ
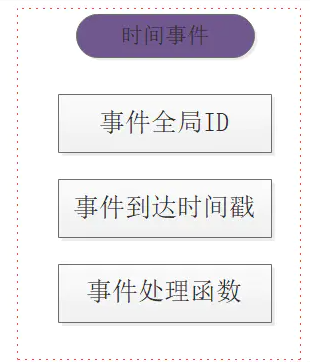
ПЩМћ RedisЕФжмЦкадЪТМўЫфШЛжївЊДІРэИЈжњШЮЮёЃЌЕЋЪЧЖдећИіЗўЮёЕФЮШЖЈдЫааЃЌЦ№ЕНжСЙиживЊЕФзїгУЁЃ RedisЕФУПИіЪБМфЪТМўЗжЮЊШ§ИіВПЗжЃК - ЪТМўID ШЋОжЮЈвЛ вРДЮЕнді
- ДЅЗЂЪБМфДС msМЖОЋЖШ
- ЪТМўДІРэКЏЪ§ ЪТМўЛиЕїКЏЪ§
ЪБМфЪТМўTime_EventНсЙЙЃК
RedisЕФЪБМфЪТМўЪЧДцДЂдкСДБэжаЕФЃЌВЂЧвЪЧАДееIDДцДЂЕФЃЌаТЪТМўдкЭЗВПОЩЪТМўдкЮВВПЃЌЕЋЪЧВЂВЛЪЧАДееМДНЋБЛжДааЕФЫГађДцДЂЕФЁЃ вВОЭЪЧЕквЛИідЊЫи50msКѓжДааЃЌЕЋЪЧЕкШ§ИіПЩФм30msКѓжДааЃЌетбљЕФЛАRedisУПДЮДгСДБэжаЛёШЁзюНќвЊжДааЕФЪТМўЪБЃЌЖМашвЊНјааO(N)БщРњЃЌЯдШЛадФмВЛЪЧзюКУЕФЃЌзюКУЕФЧщПіПЯЖЈЪЧРрЫЦгкзюаЁеЛMinStackЕФЫМТЗЃЌШЛЖјAntirezДѓРаШДбЁдёСЫЮоађСДБэЕФЗНЪНЁЃ бЁдёЮоађСДБэвВЪЧЪЪКЯRedisГЁОАЕФЃЌвђЮЊRedisжаЕФЪБМфЪТМўЪ§СПВЂВЛЖрЃЌМДЪЙНјааO(N)БщРњадФмЫ№ЪЇвВЮЂКѕЦфЮЂЃЌвВОЭВЛБиУПДЮВхШыаТЪТМўЪБНјааСДБэжиХХЁЃ RedisДцДЂЪБМфЪТМўЕФЮоађСДБэШчЭМЃК
5.3 ЕЅЯпГЬФЃЪНжаЪТМўЕїЖШКЭжДааRedisЗўЮёжавђЮЊАќКЌСЫЪБМфЪТМўКЭЮФМўЪТМўЃЌЪТЧщвВОЭБфЕУИДдгСЫЃЌЗўЮёЦївЊОіЖЈКЮЪБДІРэЮФМўЪТМўЁЂКЮЪБДІРэЪБМфЪТМўЁЂВЂЧвЛЙвЊУїШЗжЊЕРДІРэЪБМфЕФЪБМфГЄЖШЃЌвђДЫЪТМўЕФжДааКЭЕїЖШОЭГЩЮЊжиЕуЁЃ RedisЗўЮёЦїЛсТжСїДІРэЮФМўЪТМўКЭЪБМфЪТМўЃЌетСНжжЪТМўЕФДІРэЖМЪЧЭЌВНЁЂгаађЁЂдзгЕижДааЕФЃЌЗўЮёЦївВВЛЛсжежЙе§дкжДааЕФЪТМўЃЌвВВЛЛсЖдЪТМўНјааЧРеМЁЃ ЮФМўЪТМўЪЧЫцЛњГіЯжЕФЃЌШчЙћДІРэЭъГЩвЛДЮЮФМўЪТМўКѓЃЌвРОЩУЛгаЦфЫћЮФМўЪТМўЕНРДЃЌЗўЮёЦїНЋМЬајЕШД§ЃЌдкЮФМўЪТМўЕФВЛЖЯжДаажаЃЌЪБМфЛсж№НЅЯђзюдчЕФЪБМфЪТМўЫљЩшжУЕФЕНДяЪБМфБЦНќВЂзюжеРДЕНЕНДяЪБМфЃЌетЪБЗўЮёЦїОЭПЩвдПЊЪМДІРэЕНДяЕФЪБМфЪТМўСЫЁЃ гЩгкЪБМфЪТМўдкЮФМўЪТМўжЎКѓжДааЃЌВЂЧвЪТМўжЎМфВЛЛсГіЯжЧРеМЃЌЫљвдЪБМфЪТМўЕФЪЕМЪДІРэЪБМфвЛАуЛсБШЩшЖЈЕФЪБМфЩдЭэвЛаЉЁЃ RedisдДТыae.cжаЖдЪТМўЕїЖШКЭжДааЕФЯъЯИЙ§ГЬдкaeProcessEventsжаЪЕЯжЕФЃЌОпЬхЕФДњТыШчЯТЃК int aeProcessEvents(aeEventLoop *eventLoop, int flags){ int processed = 0, numevents; if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0; if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) { int j; aeTimeEvent *shortest = NULL; struct timeval tv, *tvp; if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT)) shortest = aeSearchNearestTimer(eventLoop); if (shortest) { long now_sec, now_ms; aeGetTime(&now_sec, &now_ms); tvp = &tv; long long ms = (shortest->when_sec - now_sec)*1000 + shortest->when_ms - now_ms; if (ms > 0) { tvp->tv_sec = ms/1000; tvp->tv_usec = (ms % 1000)*1000; } else { tvp->tv_sec = 0; tvp->tv_usec = 0; } } else { if (flags & AE_DONT_WAIT) { tv.tv_sec = tv.tv_usec = 0; tvp = &tv; } else { tvp = NULL; /* wait forever */ } } numevents = aeApiPoll(eventLoop, tvp); if (eventLoop->aftersleep != NULL && flags & AE_CALL_AFTER_SLEEP) eventLoop->aftersleep(eventLoop); for (j = 0; j < numevents; j++) { aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd]; int mask = eventLoop->fired[j].mask; int fd = eventLoop->fired[j].fd; int fired = 0; int invert = fe->mask & AE_BARRIER; if (!invert && fe->mask & mask & AE_READABLE) { fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; } if (fe->mask & mask & AE_WRITABLE) { if (!fired || fe->wfileProc != fe->rfileProc) { fe->wfileProc(eventLoop,fd,fe->clientData,mask); fired++; } } if (invert && fe->mask & mask & AE_READABLE) { if (!fired || fe->wfileProc != fe->rfileProc) { fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; } } processed++; } } /* Check time events */ if (flags & AE_TIME_EVENTS) processed += processTimeEvents(eventLoop); return processed;}
ЩЯУцЕФдДТыПЩФмЖСЦ№РДВЂВЛжБЙлЃЌдкЁЖRedisЩшМЦгыЪЕЯжЁЗЪщжаИјГіСЫЮБДњТыЪЕЯжЃК def aeProcessEvents() #ЛёШЁЕБЧАзюНќЕФД§жДааЕФЪБМфЪТМў time_event = aeGetNearestTimer() #МЦЫузюНќжДааЪТМўгыЕБЧАЪБМфЕФВюжЕ remain_gap_time = time_event.when - uinx_time_now() #ХаЖЯЪБМфЪТМўЪЧЗёвбОЕНЦк дђжижУ ТэЩЯжДаа if remain_gap_time < 0: remain_gap_time = 0 #зшШћЕШД§ЮФМўЪТМў ОпЬхЕФзшШћЕШД§ЪБМфгЩremain_gap_timeОіЖЈ #ШчЙћremain_gap_timeЮЊ0 ФЧУДВЛзшШћСЂПЬЗЕЛи aeApiPoll(remain_gap_time) #ДІРэЫљгаЮФМўЪТМў ProcessAllFileEvent() #ДІРэЫљгаЪБМфЪТМў ProcessAllTimeEvent()
ПЩвдПДЕНRedisЗўЮёЦїЪЧБпзшШћБпжДааЕФЃЌОпЬхЕФзшШћЪТМўгЩзюНќД§жДааЪБМфЪТМўЕФЕШД§ЪБМфОіЖЈЕФЃЌдкзшШћИУзюаЁЕШД§ЪБМфЗЕЛижЎКѓЃЌПЊЪМДІРэЪТМўШЮЮёЃЌВЂЧвЯШжДааЮФМўЪТМўЁЂдйжДааЪБМфЪТМўЃЌЫљгаМДЪЙЪБМфЪТМўвЊМДПЬжДааЃЌвВашвЊЕШД§ЮФМўЪТМўЭъГЩжЎКѓдйжДааЪБМфЪТМўЃЌЫљвдБШдЄЦкЕФЩдЭэЁЃ
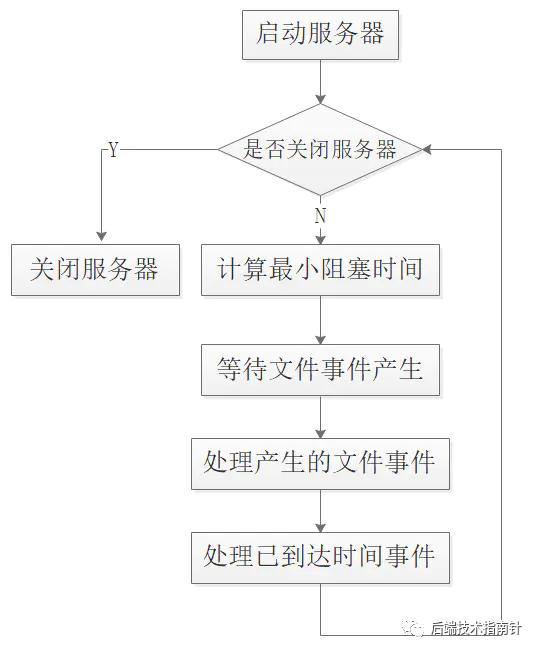
0x06. ЬИЬИЖдRedisЕФЗДгІЖбФЃЪНЕФШЯЪЖRedisЛљгкReactorФЃЪН(ЗДгІЖбФЃЪН)ПЊЗЂСЫздМКЕФЭјТчФЃаЭЃЌаЮГЩСЫвЛИіЭъБИЕФЛљгкIOИДгУЕФЪТМўЧ§ЖЏЗўЮёЦїЃЌЕЋЪЧВЛгЩЕУИЁЯжМИИіЮЪЬт: - ЮЊЪВУДвЊЪЙгУReactorФЃЪНФиЃП
- RedisШчКЮЪЕЯжздМКЕФReactorФЃЪНЃП
6.1 ReactorФЃЪНЕЅДПЕФepoll/kqueueПЩвдЕЅЛњжЇГжЪ§ЭђВЂЗЂЃЌЕЅДПДгадФмЕФНЧЖШЖјбдКСЮоЮЪЬтЃЌЕЋЪЧММЪѕЪЕЯжКЭШэМўЩшМЦвРОЩДцдквЛаЉВювьЁЃ ЩшЯыетбљвЛжжГЁОА: - epoll/kqueueНЋЪеМЏЕНЕФПЩЖСаДЪТМўШЋВПЗХШыЖгСажаЕШД§вЕЮёЯпГЬЕФДІРэЃЌДЫЪБЯпГЬГиЕФЙЄзїЯпГЬФУЕНШЮЮёНјааДІРэЃЌЪЕМЪГЁОАжаПЩФмгаКмЖржжЧыЧѓРраЭЃЌЙЄзїЯпГЬУПФУЕНвЛжжШЮЮёОЭНјааЯргІЕФДІРэЃЌДІРэЭъГЩжЎКѓМЬајДІРэЦфЫћРраЭЕФШЮЮё
- ЙЄзїЯпГЬашвЊЙизЂИїжжВЛЭЌРраЭЕФЧыЧѓЃЌЖдгкВЛЭЌЕФЧыЧѓбЁдёВЛЭЌЕФДІРэЗНЗЈЃЌвђДЫЧыЧѓРраЭЕФдіМгЛсШУЙЄзїЯпГЬИДдгЖШдіМгЃЌЮЌЛЄЦ№РДвВБфЕУдНРДдНРЇФб
ЩЯУцЕФГЁОАЦфЪЕКЭИпВЂЗЂЭјТчФЃаЭКмЯрЫЦЃЌШчЙћЮвУЧдкepoll/kqueueЕФЛљДЁЩЯНјаавЕЮёЧјЗжЃЌВЂЧвЖдУПвЛжжвЕЮёЩшжУЯргІЕФДІРэКЏЪ§ЃЌУПДЮРДШЮЮёжЎКѓЖдШЮЮёНјааЪЖБ№КЭЗжЗЂЃЌУПжжДІРэКЏЪ§жЛДІРэвЛжжвЕЮёЃЌетжжФЃаЭИќМгЗћКЯOOЕФЩшМЦРэФюЃЌетвВЪЧReactorЗДгІЖбФЃЪНЕФЩшМЦЫМТЗЁЃ ЗДгІЖбФЃЪНЪЧвЛжжЖдЯѓааЮЊЕФЩшМЦФЃЪНЃЌжївЊЭЌгкЭЌВНIOЃЌвьВНIOгаProactorФЃЪНЃЌетРяВЛЯъЯИНВЪіProactorФЃЪНЃЌЖўепЕФжївЊЧјБ№ОЭЪЧReactorЪЧЭЌВНIO,ProactorЪЧвьВНIOЃЌРэТлЩЯProactorаЇТЪИќИпЃЌЕЋЪЧProactorФЃЪНашвЊВйзїЯЕЭГдкФкКЫВуУцЖдвьВНIOНјаажЇГжЃЌLinuxЕФBoost.asioОЭЪЧProactorФЃЪНЕФДњБэЃЌWindowsгаIOCPЁЃ ЭјЩЯБШНЯОЕфЕФвЛеХReactorФЃЪНЕФРрЭМ:
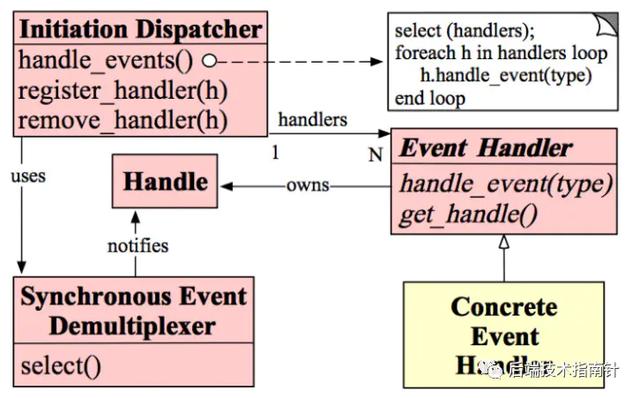
ЭМжаИјГіСЫ5ИіВПМўЗжБ№ЮЊЃК - handle ПЩвдРэНтЮЊЖСаДЪТМў ПЩвдзЂВсЕНReactorНјааМрПи
- Sync event demultiplexer ПЩвдРэНтЮЊepoll/kqueue/selectЕШзїЮЊIOЪТМўЕФВЩМЏЦї
- Dispatcher ЬсЙЉзЂВс/ЩОГ§ЪТМўВЂНјааЗжЗЂЃЌзїЮЊЪТМўЗжЗЂЦї
- Event Handler ЪТМўДІРэЦї ЭъГЩОпЬхЪТМўЕФЛиЕї ЙЉDispatcherЕїгУ
- Concrete Event Handler ОпЬхЧыЧѓДІРэКЏЪ§
ИќМђНрЕФСїГЬШчЯТЃК
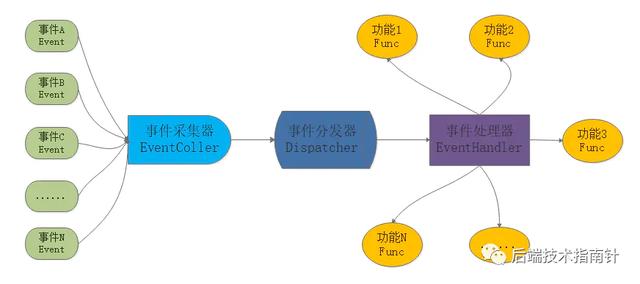
бЛЗЧАЯШНЋД§МрПиЕФЪТМўНјаазЂВсЃЌЕБМрПижаЕФSocketЖСаДЪТМўЕНРДЪБЃЌЪТМўВЩМЏЦїepollЕШIOИДгУЙЄОпМьВтЕНВЂЧвНЋЪТМўЗЕЛиИјЪТМўЗжЗЂЦїDispatcherЃЌЗжЗЂЦїИљОнЖСЁЂаДЁЂвьГЃЕШЧщПіНјааЗжЗЂИјЪТМўДІРэЦїЃЌЪТМўДІРэЦїНјЖјИљОнЪТМўОпЬхРраЭРДЕїЖШЯргІЕФЪЕЯжКЏЪ§РДЭъГЩШЮЮёЁЃ 6.2 ReactorФЃЪНдкRedisжаЕФЪЕЯжRedisДІРэПЭЛЇЖЫвЕЮё(ЮФМўЪТМў)ЕФЛљБОСїГЬЃК
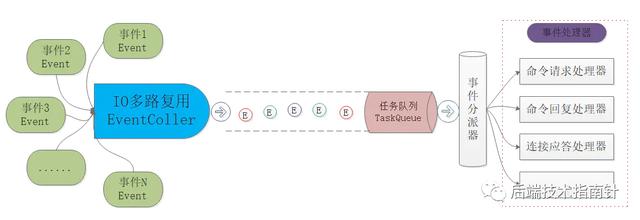
RedisЕФIOИДгУЕФбЁдё #ifdef HAVE_EVPORT#include "ae_evport.c"#else #ifdef HAVE_EPOLL #include "ae_epoll.c" #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" #else #include "ae_select.c" #endif #endif#endif
RedisжажЇГжЖржжIOИДгУЃЌдДТыжаЪЙгУЯргІЕФКъЖЈвхНјаабЁдёЃЌБрвыЪБОЭПЩвдЛёШЁЕБЧАЯЕЭГжЇГжЕФзюгХЕФIOИДгУКЏЪ§РДЪЙгУЃЌДгЖјЪЕЯжСЫRedisЕФгХауЕФПЩвЦжВЬиадЁЃ
гЩгкRedisЕФЪЧЕЅЯпГЬДІРэвЕЮёЕФЃЌвђДЫIOИДгУГЬађНЋЖСаДЪТМўЭЌВНЕФж№вЛЗХШыЖгСажаЃЌШчЙћЕБЧАЖгСавбОТњСЫЃЌФЧУДжЛФмГівЛИіШывЛИіЃЌЕЋЪЧгЩгкRedisе§ГЃЧщПіЯТДІРэЕУКмПьЃЌВЛЬЋЛсГіЯжЖгСаТњГйГйЮоЗЈЗХШЮЮёЕФЧщПіЃЌЕЋЪЧЕБжДааФГаЉзшШћВйзїЪБНЋЕМжТГЄЪБМфЕФзшШћЃЌЮоЗЈДІРэаТШЮЮёЁЃ ЪТМўЕФПЩЖСаДЪЧДгЗўЮёЦїНЧЖШПДЕФЃЌЗжХЩПДЕНЕФЪТМўРраЭАќРЈЃК - AE_READABLE ПЭЛЇЖЫаДЪ§ОнЁЂЙиБеСЌНгЁЂаТСЌНгЕНДя
- AE_WRITEABLE ПЭЛЇЖЫЖСЪ§Он
ЬиБ№ЕиЃЌЕБвЛИіЬзНгзжСЌНгЭЌЪБПЩЖСПЩаДЪБЃЌЗўЮёЦїЛсгХЯШДІРэЖСЪТМўдйДІРэаДЪТМўЃЌвВОЭЪЧЖСгХЯШЁЃ RedisНЋЮФМўЪТМўНјааЙщРрЃЌБраДСЫЖрИіЪТМўДІРэЦїКЏЪ§ЃЌЦфжаАќРЈЃК - СЌНггІД№ДІРэЦїЃКЪЕЯжаТСЌНгЕФНЈСЂ
- УќСюЧыЧѓДІРэЦїЃКДІРэПЭЛЇЖЫЕФаТУќСю
- УќСюЛиИДДІРэЦїЃКЗЕЛиПЭЛЇЖЫЕФЧыЧѓНсЙћ
- ИДжЦДІРэЦїЃКЪЕЯжжїДгЗўЮёЦїЕФЪ§ОнИДжЦ
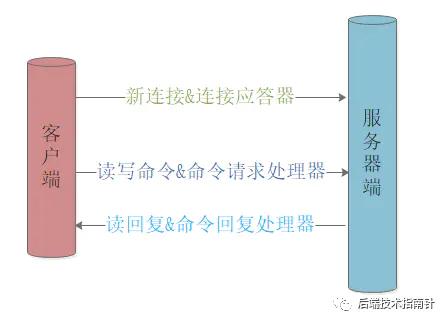
RedisЗўЮёЦїЕФжїЯпГЬДІгкбЛЗжаЃЌДЫЪБClientЯђRedisЗўЮёЦїЗЂЦ№СЌНгЧыЧѓЃЌМйШчЪЧ6379ЖЫПкЃЌМрЬ§ЖЫПкдкIOИДгУЙЄОпЯТМьВтЕНAE_READABLEЪТМўЃЌВЂНЋИУЪТМўЗХШыTaskQueueжаЃЌЕШД§БЛДІРэЃЌЪТМўЗжХЩЦїЛёШЁетИіЖСЪТМўЃЌНјвЛВНШЗЖЈЪЧаТСЌНгЧыЧѓЃЌОЭНЋИУЪТМўНЛИјСЌНггІД№ДІРэЦїНЈСЂСЌНгЃЛ НЈСЂСЌНгКѓClientЯђЗўЮёЦїЗЂЫЭСЫвЛИіgetУќСюЃЌвРОЩБЛIOИДгУМьВтДІРэЗХШыЖгСаЃЌБЛЪТМўЗжХЩЦїДІРэжИХЩИјУќСюЧыЧѓДІРэЦїЃЌЕїгУЯргІГЬађНјаажДааЃЛ ЗўЮёЦїНЋЬзНгзжЕФAE_WRITEABLEЪТМўгыУќСюЛиИДДІРэЦїЯрЙиСЊЃЌЕБПЭЛЇЖЫГЂЪдЖСШЁНсЙћЪБВњЩњПЩаДЪТМўЃЌДЫЪБЗўЮёЦїЖЫДЅЗЂУќСюЛиИДЯьгІЃЌВЂНЋЪ§ОнНсЙћаДШыЬзНгзжЃЌЭъГЩжЎКѓЗўЮёЖЫНгДЅИУЬзНгзжгыУќСюЛиИДДІРэЦїжЎМфЕФЙиСЊЃЛ
x07. RedisЪЧШчКЮзіГжОУЛЏЕФМАЦфЛљБОдРэЭЈЫзНВГжОУЛЏОЭЪЧНЋФкДцжаЕФЪ§ОнаДШыЗЧвзЪЇНщжЪжаЃЌБШШчЛњаЕДХХЬКЭSSDЁЃ дкЗўЮёЦїЗЂЩњхДЛњЪБЃЌзїЮЊФкДцЪ§ОнПтRedisРяЕФЫљгаЪ§ОнНЋЛсЖЊЪЇЃЌвђДЫRedisЬсЙЉСЫГжОУЛЏСНДѓРћЦїЃКRDBКЭAOF - RDB НЋЪ§ОнПтПьеевдЖўНјжЦЕФЗНЪНБЃДцЕНДХХЬжаЁЃ
- AOF вдавщЮФБОЗНЪНЃЌНЋЫљгаЖдЪ§ОнПтНјааЙ§аДШыЕФУќСюКЭВЮЪ§МЧТМЕН AOF ЮФМўЃЌДгЖјМЧТМЪ§ОнПтзДЬЌЁЃ
[redis@abc]$ cat /abc/redis/conf/redis.conf save 900 1 save 300 10 save 60 10000 dbfilename "dump.rdb" dir "/data/dbs/redis/rdbstro"
ЧАШ§ааЖМЪЧЖдДЅЗЂRDBЕФвЛИіЬѕМўЃЌ ШчЕквЛааБэЪОУП900УыжггавЛЬѕЪ§ОнБЛаоИФдђДЅЗЂRDBЃЌвРДЮРрЭЦЃЛжЛвЊвЛЬѕТњзуОЭЛсНјааRDBГжОУЛЏЃЛ ЕкЫФааdbfilenameжИЖЈСЫАбФкДцРяЕФЪ§ОнПтаДШыБОЕиЮФМўЕФУћГЦЃЌИУЮФМўЪЧНјаабЙЫѕКѓЕФЖўНјжЦЮФМўЃЛ ЕкЮхааdirжИЖЈСЫRDBЖўНјжЦЮФМўДцЗХФПТМ ЃЛ дкУќСюааРяНјааХфжУ,ЗўЮёЦїжиЦєВХЛсЩњаЇ: [redis@abc]$ bin/redis-cli127.0.0.1:6379> CONFIG GET save 1) "save"2) "900 1 300 10 60 10000"127.0.0.1:6379> CONFIG SET save "21600 1000" OK
7.1 RDBЕФSAVEКЭBGSAVERDBЮФМўЪЪКЯЪ§ОнЕФШнджБИЗнгыЛжИДЃЌЭЈЙ§RDBЮФМўЛжИДЪ§ОнПтКФЪБНЯЖЬЃЌПЩвдПьЫйЛжИДЪ§ОнЁЃ RDBГжОУЛЏжЛЛсжмЦкадЕФБЃДцЪ§ОнЃЌдкЮДДЅЗЂЯТвЛДЮДцДЂЪБЗўЮёхДЛњЃЌОЭЛсЖЊЪЇдіСПЪ§ОнЁЃЕБЪ§ОнСПНЯДѓЕФЧщПіЯТЃЌforkзгНјГЬетИіВйзїКмЯћКФcpuЃЌПЩФмЛсЗЂЩњГЄДяУыМЖБ№ЕФзшШћЧщПіЁЃ SAVEЪЧзшШћЪНГжОУЛЏЃЌжДааУќСюЪБRedisжїНјГЬАбФкДцЪ§ОнаДШыЕНRDBЮФМўжажБЕНДДНЈЭъБЯЃЌЦкМфRedisВЛФмДІРэШЮКЮУќСюЁЃ BGSAVEЪєгкЗЧзшШћЪНГжОУЛЏЃЌДДНЈвЛИізгНјГЬАбФкДцжаЪ§ОнаДШыRDBЮФМўРяЭЌЪБжїНјГЬДІРэУќСюЧыЧѓЁЃ ШчЭМеЙЪОСЫbgsaveЕФМђЕЅСїГЬЃК
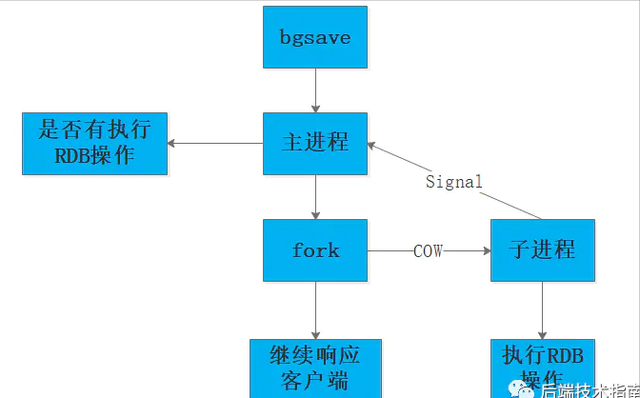
RDBЗНЪНЕФГжОУЛЏЪЧЭЈЙ§ПьееЪЕЯжЕФЃЌЗћКЯЬѕМўЪБRedisЛсздЖЏНЋФкДцЪ§ОнНјааПьееВЂДцДЂдкгВХЬЩЯЃЌвдBGSAVEЮЊР§ЃЌвЛДЮЭъећЪ§ОнПьееЕФЙ§ГЬЃК - RedisЪЙгУforkКЏЪ§ДДНЈзгНјГЬЃЛ
- ИИНјГЬМЬајНгЪеВЂДІРэУќСюЧыЧѓЃЌзгНјГЬНЋФкДцЪ§ОнаДШыСйЪБЮФМўЃЛ
- згНјГЬаДШыЫљгаЪ§ОнКѓЛсгУСйЪБЮФМўЬцЛЛОЩRDBЮФМўЃЛ
жДааforkЕФЪБOSЛсЪЙгУаДЪБПНБДВпТдЃЌЖдзгНјГЬНјааПьееЙ§ГЬгХЛЏЁЃ RedisдкНјааПьееЙ§ГЬжаВЛЛсаоИФRDBЮФМўЃЌжЛгаПьееНсЪјКѓВХЛсНЋОЩЕФЮФМўЬцЛЛГЩаТЕФЃЌвВОЭЪЧШЮКЮЪБКђRDBЮФМўЖМЪЧЭъећЕФЁЃ ЮвУЧПЩвдЭЈЙ§ЖЈЪББИЗнRDBЮФМўРДЪЕЯжRedisЪ§ОнПтБИЗнЃЌRDBЮФМўЪЧОЙ§бЙЫѕЕФЃЌеМгУЕФПеМфЛсаЁгкФкДцжаЕФЪ§ОнДѓаЁЁЃ Г§СЫздЖЏПьееЛЙПЩвдЪжЖЏЗЂЫЭSAVEЛђBGSAVEУќСюШУRedisжДааПьееЁЃЭЈЙ§RDBЗНЪНЪЕЯжГжОУЛЏЃЌгЩгкRDBБЃДцЦЕТЪЕФЯожЦЃЌШчЙћЪ§ОнКмживЊдђПМТЧЪЙгУAOFЗНЪННјааГжОУЛЏЁЃ 7.2 AOFЯъНтдкЪЙгУAOFГжОУЛЏЗНЪНЪБЃЌRedisЛсНЋУПвЛИіЪеЕНЕФаДУќСюЖМЭЈЙ§WriteКЏЪ§зЗМгЕНЮФМўжаРрЫЦгкMySQLЕФbinlogЁЃЛЛбджЎAOFЪЧЭЈЙ§БЃДцЖдredisЗўЮёЖЫЕФаДУќСюРДМЧТМЪ§ОнПтзДЬЌЕФЁЃ AOFЮФМўгаздМКЕФДцДЂавщИёЪНЃК [redis@abc]$ more appendonly.aof *2 # 2ИіВЮЪ§$6 # ЕквЛИіВЮЪ§ГЄЖШЮЊ 6SELECT # ЕквЛИіВЮЪ§$1 # ЕкЖўВЮЪ§ГЄЖШЮЊ 18 # ЕкЖўВЮЪ§*3 # 3ИіВЮЪ§$3 # ЕквЛИіВЮЪ§ГЄЖШЮЊ 4SET # ЕквЛИіВЮЪ§$4 # ЕкЖўВЮЪ§ГЄЖШЮЊ 4name # ЕкЖўИіВЮЪ§$4 # ЕкШ§ИіВЮЪ§ГЄЖШЮЊ 4Jhon # ЕкЖўВЮЪ§ГЄЖШЮЊ 4
AOFХфжУЃК [redis@abc]$ more ~/redis/conf/redis.confdir "/data/dbs/redis/abcd" #AOFЮФМўДцЗХФПТМappendonly yes #ПЊЦєAOFГжОУЛЏЃЌФЌШЯЙиБеappendfilename "appendonly.aof" #AOFЮФМўУћГЦЃЈФЌШЯЃЉappendfsync no #AOFГжОУЛЏВпТдauto-aof-rewrite-percentage 100 #ДЅЗЂAOFЮФМўжиаДЕФЬѕМўЃЈФЌШЯЃЉauto-aof-rewrite-min-size 64mb #ДЅЗЂAOFЮФМўжиаДЕФЬѕМўЃЈФЌШЯЃЉ
ЕБПЊЦєAOFКѓЃЌЗўЮёЖЫУПжДаавЛДЮаДВйзїОЭЛсАбИУЬѕУќСюзЗМгЕНвЛИіЕЅЖРЕФAOFЛКГхЧјЕФФЉЮВЃЌШЛКѓАбAOFЛКГхЧјЕФФкШнаДШыAOFЮФМўРяЃЌгЩгкДХХЬЛКГхЧјЕФДцдкаДШыAOFЮФМўжЎКѓЃЌВЂВЛДњБэЪ§ОнвбОТфХЬСЫЃЌЖјКЮЪБНјааЮФМўЭЌВНдђЪЧИљОнХфжУЕФappendfsyncРДНјааХфжУЃК appendfsyncбЁЯюЃКalwaysЁЂeverysecКЭnoЃК - alwaysЃКЗўЮёЦїдкУПжДаавЛИіЪТМўОЭАбAOFЛКГхЧјЕФФкШнЧПжЦадЕФаДШыгВХЬЩЯЕФAOFЮФМўРяЃЌБЃжЄСЫЪ§ОнГжОУЛЏЕФЭъећадЃЌаЇТЪЪЧзюТ§ЕФЕЋзюАВШЋЕФЃЛ
- everysecЃКЗўЮёЖЫУПИєвЛУыВХЛсНјаавЛДЮЮФМўЭЌВНАбФкДцЛКГхЧјРяЕФAOFЛКДцЪ§Онеце§аДШыAOFЮФМўРяЃЌМцЙЫСЫаЇТЪКЭЭъећадЃЌМЋЖЫЧщПіЗўЮёЦїхДЛњжЛЛсЖЊЪЇвЛУыФкЖдRedisЪ§ОнПтЕФаДВйзїЃЛ
- noЃКБэЪОФЌШЯЯЕЭГЕФЛКДцЧјаДШыДХХЬЕФЛњжЦЃЌВЛзіГЬађЧПжЦЃЌЪ§ОнАВШЋадКЭЭъећадВювЛаЉЁЃ
AOFБШRDBЮФМўИќДѓЃЌВЂЧвдкДцДЂУќСюЕФЙ§ГЬжадіГЄИќПьЃЌЮЊСЫбЙЫѕAOFЕФГжОУЛЏЮФМўЃЌRedisЬсЙЉСЫжиаДЛњжЦвдДЫРДЪЕЯжПижЦAOFЮФМўЕФдіГЄЁЃ AOFжиаДЪЕЯжЕФРэТлЛљДЁЪЧетбљЕФЃК - жДааset hello world 50ДЮ
- зюКѓжДаавЛДЮ set hello china
- зюжеЖдгкAOFЮФМўЖјбдЧАУц50ДЮЖМЪЧЮовтвхЕФЃЌAOFжиаДОЭЪЧНЋkeyжЛБЃДцзюКѓЕФзДЬЌЁЃ
- жиаДЦкМфЕФЪ§ОнвЛжТадЮЪЬт
згНјГЬдкНјаа AOF жиаДЦкМфЃЌ жїНјГЬЛЙашвЊМЬајДІРэУќСюЃЌ ЖјаТЕФУќСюПЩФмЖдЯжгаЕФЪ§ОнНјаааоИФЃЌ ЛсГіЯжЪ§ОнПтЕФЪ§ОнКЭжиаДКѓЕФ AOF ЮФМўжаЕФЪ§ОнВЛвЛжТЁЃ вђДЫRedis діМгСЫвЛИі AOF жиаДЛКДцЃЌ етИіЛКДцдк fork ГізгНјГЬжЎКѓПЊЪМЦєгУЃЌ Redis жїНјГЬдкНгЕНаТЕФаДУќСюжЎКѓЃЌ Г§СЫЛсНЋетИіаДУќСюЕФавщФкШнзЗМгЕНЯжгаЕФ AOF ЮФМўжЎЭтЃЌ ЛЙЛсзЗМгЕНетИіЛКДцжаЁЃ
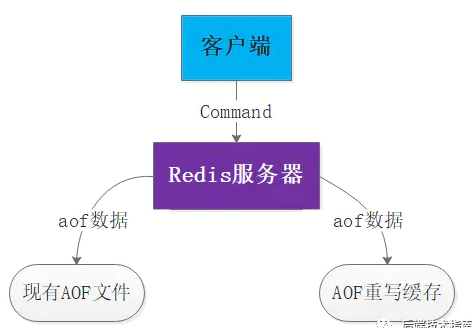
ЕБзгНјГЬЭъГЩ AOF жиаДжЎКѓЯђИИНјГЬЗЂЫЭвЛИіЭъГЩаХКХЃЌ ИИНјГЬдкНгЕНЭъГЩаХКХжЎКѓЛсЕїгУаХКХДІРэКЏЪ§ЃЌЭъГЩвдЯТЙЄзїЃК - НЋ AOF жиаДЛКДцжаЕФФкШнШЋВПаДШыЕНаТ AOF ЮФМўжа
- ЖдаТЕФ AOF ЮФМўНјааИФУћЃЌИВИЧдгаЕФ AOF ЮФМў
- AOFжиаДЕФзшШћад
ећИі AOF КѓЬЈжиаДЙ§ГЬжажЛгазюКѓаДШыЛКДцКЭИФУћВйзїЛсдьГЩжїНјГЬзшШћЃЌ дкЦфЫћЪБКђAOF КѓЬЈжиаДЖМВЛЛсЖджїНјГЬдьГЩзшШћЃЌ НЋ AOF жиаДЖдадФмдьГЩЕФгАЯьНЕЕНСЫзюЕЭЁЃ AOF жиаДПЩвдгЩгУЛЇЭЈЙ§ЕїгУ BGREWRITEAOF ЪжЖЏДЅЗЂЁЃ ЗўЮёЦїдк AOF ЙІФмПЊЦєЕФЧщПіЯТЃЌЛсЮЌГжвдЯТШ§ИіБфСПЃК - ЕБЧА AOF ЮФМўДѓаЁ
- зюКѓвЛДЮ жиаДжЎКѓЃЌ AOF ЮФМўДѓаЁЕФБфСП
- AOFЮФМўДѓаЁдіГЄАйЗжБШ
УПДЮЕБ serverCron КЏЪ§жДааЪБЃЌ ЫќЖМЛсМьВщвдЯТЬѕМўЪЧЗёШЋВПТњзуЃЌ ШчЙћЪЧЕФЛАЃЌ ОЭЛсДЅЗЂздЖЏЕФ AOF жиаДЃК - УЛга BGSAVE УќСюдкНјаа ЗРжЙгыRDBЕФГхЭЛ
- УЛга BGREWRITEAOF дкНјаа ЗРжЙКЭЪжЖЏAOFГхЭЛ
- ЕБЧА AOF ЮФМўДѓаЁжСЩйДѓгкЩшЖЈжЕ ЛљБОвЊЧѓ ЬЋаЁУЛвтвх
- ЕБЧА AOF ЮФМўДѓаЁКЭзюКѓвЛДЮ AOF жиаДКѓЕФДѓаЁжЎМфЕФБШТЪДѓгкЕШгкжИЖЈЕФдіГЄАйЗжБШ
7.3 RedisЕФЪ§ОнЛжИДRedisЕФЪ§ОнЛжИДгХЯШМЖ - ШчЙћжЛХфжУ AOF ЃЌжиЦєЪБМгди AOF ЮФМўЛжИДЪ§ОнЃЛ
- ШчЙћЭЌЪБХфжУСЫ RDB КЭ AOF ЃЌЦєЖЏжЛМгди AOF ЮФМўЛжИДЪ§ОнЃЛ
- ШчЙћжЛХфжУ RDBЃЌЦєЖЏНЋМгди dump ЮФМўЛжИДЪ§ОнЁЃ
ПНБД AOF ЮФМўЕН Redis ЕФЪ§ОнФПТМЃЌЦєЖЏ redis-server AOF ЕФЪ§ОнЛжИДЙ§ГЬ:Redis ащФтвЛИіПЭЛЇЖЫЃЌЖСШЁAOFЮФМўЛжИД Redis УќСюКЭВЮЪ§ЃЌШЛКѓжДааУќСюДгЖјЛжИДЪ§ОнЃЌетаЉЙ§ГЬжївЊдкloadAppendOnlyFile() жаЪЕЯжЁЃ ПНБД RDB ЮФМўЕН Redis ЕФЪ§ОнФПТМЃЌЦєЖЏ redis-serverМДПЩЃЌвђЮЊRDBЮФМўКЭжиЦєЧАБЃДцЕФЪЧецЪЕЪ§ОнЖјВЛЪЧУќСюзДЬЌКЭВЮЪ§ЁЃ аТаЭЕФЛьКЯаЭГжОУЛЏ RDBКЭAOFЖМгаИїздЕФШБЕуЃК - RDBЪЧУПИєвЛЖЮЪБМфГжОУЛЏвЛДЮ, ЙЪеЯЪБОЭЛсЖЊЪЇхДЛњЪБПЬгыЩЯвЛДЮГжОУЛЏжЎМфЕФЪ§ОнЃЌЮоЗЈБЃжЄЪ§ОнЭъећад
- AOFДцДЂЕФЪЧжИСюађСа, ЛжИДжиЗХЪБвЊЛЈЗбКмГЄЪБМфВЂЧвЮФМўИќДѓ
Redis 4.0 ЬсЙЉСЫИќКУЕФЛьКЯГжОУЛЏбЁЯюЃК ДДНЈГівЛИіЭЌЪБАќКЌ RDB Ъ§ОнКЭ AOF Ъ§ОнЕФ AOF ЮФМўЃЌ Цфжа RDB Ъ§ОнЮЛгк AOF ЮФМўЕФПЊЭЗЃЌ ЫќУЧДЂДцСЫЗўЮёЦїПЊЪМжДаажиаДВйзїЪБЕФЪ§ОнПтзДЬЌЃЌжСгкФЧаЉдкжиаДВйзїжДаажЎКѓжДааЕФ Redis УќСюЃЌ дђЛсМЬајвд AOF ИёЪНзЗМгЕН AOF ЮФМўЕФФЉЮВЃЌ вВМДЪЧ RDB Ъ§ОнжЎКѓЁЃ
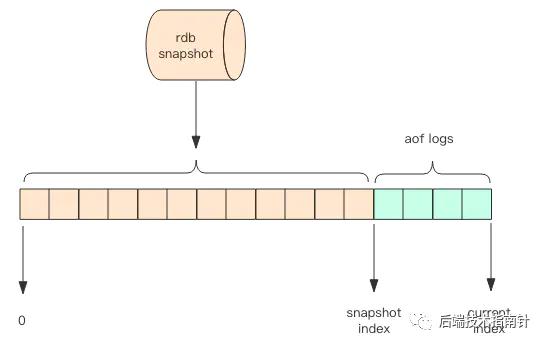
ГжОУЛЏЪЕеН дкЪЕМЪЪЙгУжаашвЊИљОнRedisзїЮЊжїДцЛЙЪЧЛКДцЁЂЪ§ОнЭъећадКЭШБЪЇадЕФвЊЧѓЁЂCPUКЭФкДцЧщПіЕШжюЖрвђЫиРДШЗЖЈЪЪКЯздМКЕФГжОУЛЏЗНАИЃЌвЛАуРДЫЕЮШЭзЕФзіЗЈАќРЈЃК - зюАВШЋЕФзіЗЈЪЧRDBгыAOFЭЌЪБЪЙгУЃЌМДЪЙAOFЫ№ЛЕЮоЗЈаоИДЃЌЛЙПЩвдгУRDBРДЛжИДЪ§ОнЃЌЕБШЛдкГжОУЛЏЪБЖдадФмвВЛсгагАЯьЁЃ
- RedisЕБМђЕЅЛКДцЃЌУЛгаЛКДцвВВЛЛсдьГЩЛКДцбЉБРжЛЪЙгУRDBМДПЩЁЃ
- ВЛЭЦМіЕЅЖРЪЙгУAOFЃЌвђЮЊAOFЖдгкЪ§ОнЕФЛжИДдиШыБШRDBТ§ЃЌЫљвдЪЙгУAOFЕФЪБКђЃЌзюКУЛЙЪЧгаRDBзїЮЊБИЗнЁЃ
- ВЩгУаТАцБОRedis 4.0ЕФГжОУЛЏаТЗНАИЁЃ
0x08.ЬИЬИRedisЕФZIPLISTЕФЕзВуЩшМЦКЭЪЕЯжЯШВЛПДRedisЕФЖдziplistЕФОпЬхЪЕЯжЃЌЮвУЧЯШРДЯывЛЯТШчЙћЮвУЧРДЩшМЦетИіЪ§ОнНсЙЙашвЊзіФФаЉЗНУцЕФПМТЧФиЃПЫМПМЪНЕФбЇЯАЪеЛёИќДѓпЯЃЁ - ПМТЧЕу1ЃКСЌајФкДцЕФЫЋУцад
СЌајаЭФкДцМѕЩйСЫФкДцЫщЦЌЃЌЕЋЪЧСЌајДѓФкДцгжВЛШнвзТњзуЁЃетИіЗЧГЃКУРэНтЃЌФуКЭКУЛљгбШ§ШЫШЅзіЕиЬњЃЌФуУЧШ§ИіАЄзХзјПЯЖЈВЛРЫЗбПеМфЃЌЕЋЪЧЕиЬњРяКмЖрШЫЖМЪЧЕЅЖРГіааЕФЃЌДѓМвЖМВЛдИвтНєАЄзХЃЌОЭетбљга2ИіЕФЮЛжУга1ИіЕФЮЛжУЃЌПЩЪЧ3ИіСЌајЕФШЗЪЕВЛКУевбНЃЌРДеХЭМЃК
- ПМТЧЕу2: бЙЫѕСаБэГадидЊЫиЕФЖрбљад
Д§ЩшМЦНсЙЙКЭЪ§зщВЛвЛбљЃЌЪ§зщЪЧвбОЧПжЦдМЖЈСЫРраЭЃЌЫљвдЮвУЧПЩвдИљОндЊЫиРраЭКЭИіЪ§РДШЗЖЈЫїв§ЕФЦЋвЦСПЃЌЕЋЪЧбЙЫѕСаБэЖддЊЫиЕФРраЭУЛгадМЪјЃЌвВОЭЪЧЫЕВЛжЊЕРЪЧЪВУДЪ§ОнРраЭКЭГЄЖШЃЌетИігаЕуЯёTCPеГАќВ№АќЕФзіЗЈСЫЃЌашвЊЮвУЧжИЖЈНсЮВЗћЛђепжИЖЈЕЅИіДцДЂЕФдЊЫиЕФГЄЖШЃЌвЊВЛШЛЪ§ОнЖМеГдквЛЦ№СЫЁЃ - ПМТЧЕу3ЃКЪєадЕФГЃЪ§МЖКФЪБЛёШЁ
ОЭЪЧЫЕЮвУЧНтОіСЫЧАУцСНЕуПМТЧЃЌЕЋЪЧзїЮЊвЛИіећЬхЃЌбЙЫѕСаБэашвЊГЃЪ§МЖЯћКФЬсЙЉвЛаЉзмЬхаХЯЂЃЌБШШчзмГЄЖШЁЂвбДцДЂдЊЫиЪ§СПЁЂЮВНкЕуЮЛжУ(ЪЕЯжЮВВПЕФПьЫйВхШыКЭЩОГ§)ЕШЃЌетбљЖдгкВйзїбЙЫѕСаБэвтвхКмДѓЁЃ - ПМТЧЕу4ЃКЪ§ОнНсЙЙЖддіЩОЕФжЇГж
РэТлЩЯЮвУЧЩшМЦЕФЪ§ОнНсЙЙвЊКмКУЕижЇГждіЩОВйзїЃЌЕБШЛЗВЪТБигаШЈКтЃЌУЛгаЪВУДЪ§ОнНсЙЙЪЧЭъУРЕФЃЌЮвУЧБпЩшМЦБпЕїећАЩЁЃ ЮвУЧвЊНкдМФкДцОЭашвЊЬиЪтЧщПіЬиЪтДІРэЃЌЫљЮНБфГЄЩшМЦЃЌвВОЭЪЧВЛЯёЫЋЯђСДБэвЛбљЙЬЖЈЪЙгУСНИіpreКЭnextжИеыРДЪЕЯжЃЌетбљПеМфЯћКФИќДѓЃЌвђДЫПЩФмашвЊЪЙгУБфГЄБрТыЁЃ ziplistзмЬхНсЙЙДѓИХЯыСЫетУДЖрЃЌЮвУЧРДПДПДRedisЪЧШчКЮПМТЧЕФЃЌБЪепгжЛСЫвЛеХзмРРМђЭМЃК
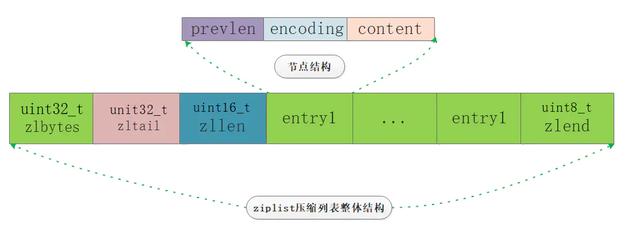
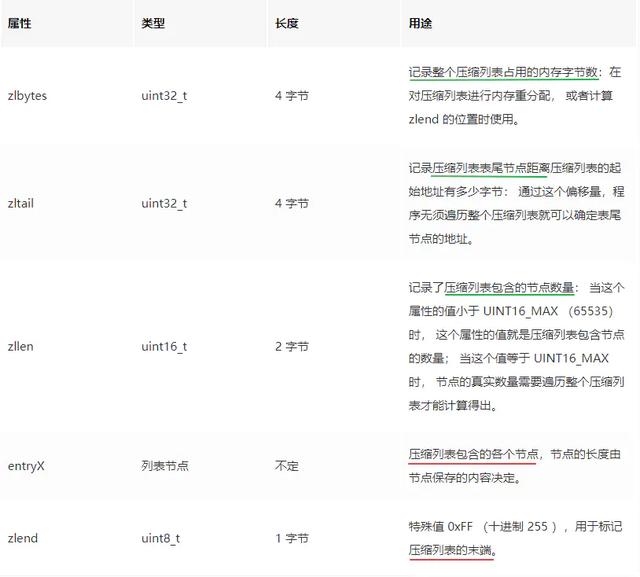
ДгЭМжаЮвУЧЛљБОЩЯПЩвдПДЕНМИИіжївЊВПЗжЃКzlbytesЁЂzltailЁЂzllenЁЂzlentryЁЂzlendЁЃ РДНтЪЭвЛЯТИїИіЪєадЕФКЌвхЃЌНшМјЭјЩЯвЛеХЗЧГЃКУЕФЭМЃЌЦфжаКьЯпбщжЄСЫЮвУЧЕФПМТЧЕу2ЁЂТЬЯпбщжЄСЫЮвУЧЕФПМТЧЕу3ЃК
РДПДЯТziplist.cжаЖдziplistЕФЩъЧыКЭРЉШнВйзїЃЌМгЩюЖдЩЯУцМИИіЪєадЕФРэНтЃК /* Create a new empty ziplist. */unsigned char *ziplistNew(void) { unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE; unsigned char *zl = zmalloc(bytes); ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); ZIPLIST_LENGTH(zl) = 0; zl[bytes-1] = ZIP_END; return zl;}/* Resize the ziplist. */unsigned char *ziplistResize(unsigned char *zl, unsigned int len) { zl = zrealloc(zl,len); ZIPLIST_BYTES(zl) = intrev32ifbe(len); zl[len-1] = ZIP_END; return zl;}
zlentryЕФЪЕЯж- encodingБрТыКЭcontentДцДЂ
ЮвУЧдйРДПДПДzlentryЕФЪЕЯжЃЌencodingЕФОпЬхФкШнШЁОігкcontentЕФРраЭКЭГЄЖШЃЌЦфжаЕБcontentЪЧзжЗћДЎЪБencodingЕФЪззжНкЕФИп2bitБэЪОзжЗћДЎРраЭЃЌЕБcontentЪЧећЪ§ЪБЃЌencodingЕФЪззжНкИп2bitЙЬЖЈЮЊ11ЃЌДгRedisдДТыЕФзЂЪЭжаПЩвдПДЕФБШНЯЧхГўЃЌБЪепЖддйзівЛВуККгяАцЕФзЂЪЭЃК /* ###########зжЗћДЎДцДЂЯъНт############### #### encodingВПЗжЗжЮЊШ§жжРраЭЃК1зжНкЁЂ2зжНкЁЂ5зжНк #### #### зюИп2bitБэЪОЪЧФФжжГЄЖШЕФзжЗћДЎ ЗжБ№ЪЧ00 01 10 ИїздЖдгІ1зжНк 2зжНк 5зжНк #### #### ЕБзюИп2bit=00ЪБ БэЪОencoding=1зжНк ЪЃгр6bit 2^6=64 ПЩБэЪОЗЖЮЇ0~63#### #### ЕБзюИп2bit=01ЪБ БэЪОencoding=2зжНк ЪЃгр14bit 2^14=16384 ПЩБэЪОЗЖЮЇ0~16383#### #### ЕБзюИп2bit=11ЪБ БэЪОencoding=5зжНк БШНЯЬиЪт гУКѓ4зжНк ЪЃгр32bit 2^32=42вкЖр#### * |00pppppp| - 1 byte * String value with length less than or equal to 63 bytes (6 bits). * "pppppp" represents the unsigned 6 bit length. * |01pppppp|qqqqqqqq| - 2 bytes * String value with length less than or equal to 16383 bytes (14 bits). * IMPORTANT: The 14 bit number is stored in big endian. * |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes * String value with length greater than or equal to 16384 bytes. * Only the 4 bytes following the first byte represents the length * up to 32^2-1. The 6 lower bits of the first byte are not used and * are set to zero. * IMPORTANT: The 32 bit number is stored in big endian. *########################зжЗћДЎДцДЂКЭећЪ§ДцДЂЕФЗжНчЯп####################* *#### Ип2bitЙЬЖЈЮЊ11 ЦфКѓ2bit ЗжБ№ЮЊ00 01 10 11 БэЪОДцДЂЕФећЪ§РраЭ * |11000000| - 3 bytes * Integer encoded as int16_t (2 bytes). * |11010000| - 5 bytes * Integer encoded as int32_t (4 bytes). * |11100000| - 9 bytes * Integer encoded as int64_t (8 bytes). * |11110000| - 4 bytes * Integer encoded as 24 bit signed (3 bytes). * |11111110| - 2 bytes * Integer encoded as 8 bit signed (1 byte). * |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer. * Unsigned integer from 0 to 12. The encoded value is actually from * 1 to 13 because 0000 and 1111 can not be used, so 1 should be * subtracted from the encoded 4 bit value to obtain the right value. * |11111111| - End of ziplist special entry.*/
contentБЃДцНкЕуФкШнЃЌЦфФкШнПЩвдЪЧзжНкЪ§зщКЭИїжжРраЭЕФећЪ§ЃЌЫќЕФРраЭКЭГЄЖШОіЖЈСЫencodingЕФБрТыЃЌЖдееЩЯУцЕФзЂЪЭРДПДСНИіР§згАЩЃК

БЃДцзжНкЪ§зщЃКБрТыЕФзюИпСНЮЛ00БэЪОНкЕуБЃДцЕФЪЧвЛИізжНкЪ§зщЃЌБрТыЕФКѓСљЮЛ001011МЧТМСЫзжНкЪ§зщЕФГЄЖШ11ЃЌcontent ЪєадБЃДцзХНкЕуЕФжЕ "hello world"ЁЃ

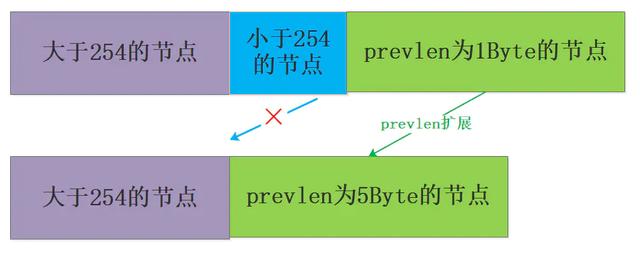
БЃДцећЪ§ЃКБрТыЮЊ11000000БэЪОНкЕуБЃДцЕФЪЧвЛИіint16_tРраЭЕФећЪ§жЕЃЌcontentЪєадБЃДцзХНкЕуЕФжЕ10086ЁЃ зюКѓРДЫЕвЛЯТprevlenетИіЪєадЃЌИУЪєадвВБШНЯЙиМќЃЌЧАУцвЛжБдкЫЕбЙЫѕСаБэЪЧЮЊСЫНкдМФкДцЩшМЦЕФЃЌШЛЖјprevlenЪєадОЭЧЁКУЦ№ЕНСЫетИізїгУЃЌЛиЯывЛЯТСДБэвЊЯыЛёШЁЧАУцЕФНкЕуашвЊЪЙгУжИеыЪЕЯжЃЌбЙЫѕСаБэгЩгкдЊЫиЕФЖрбљадвВЮоЗЈЯёЪ§зщвЛбљРДЪЕЯжЃЌЫљвдЪЙгУprevlenЪєадМЧТМЧАвЛИіНкЕуЕФДѓаЁРДНјаажИЯђЁЃ prevlenЪєадвдзжНкЮЊЕЅЮЛЃЌМЧТМСЫбЙЫѕСаБэжаЧАвЛИіНкЕуЕФГЄЖШЃЌЦфГЄЖШПЩвдЪЧ 1 зжНкЛђеп 5 зжНкЃК - ШчЙћЧАвЛНкЕуЕФГЄЖШаЁгк254зжНкЃЌФЧУДprevlenЪєадЕФГЄЖШЮЊ1зжНкЃЌ ЧАвЛНкЕуЕФГЄЖШОЭБЃДцдкетвЛИізжНкРяУцЁЃ
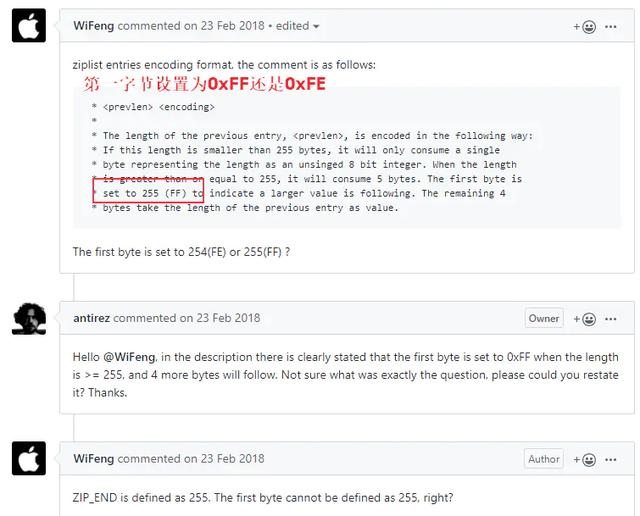
- ШчЙћЧАвЛНкЕуЕФГЄЖШДѓгкЕШгк254зжНкЃЌФЧУДprevlenЪєадЕФГЄЖШЮЊ5зжНк,ЕквЛзжНкЛсБЛЩшжУЮЊ0xFEЃЌжЎКѓЕФЫФИізжНкдђгУгкБЃДцЧАвЛНкЕуЕФГЄЖШЁЃ
ЫМПМЃКзЂвтвЛЯТетРяЕФЕквЛзжНкЩшжУЕФЪЧ0xFEЖјВЛЪЧ0xFFЃЌЯыЯТетЪЧЮЊЪВУДФиЃП УЛДэЃЁЧАУцЬсЕНСЫzlendЪЧИіЬиЪтжЕЩшжУЮЊ0xFFБэЪОбЙЫѕСаБэЕФНсЪјЃЌвђДЫетРяВЛПЩвдЩшжУЮЊ0xFFЃЌЙигкетИіЮЪЬтдкredisгаИіissueЃЌгаШЫЬсГіРДantirezЕФziplistжаЕФзЂЪЭаДЕФВЛЖдЃЌзюжеantirezЗЂЯжзЂЪЭаДДэСЫЃЌШЛКѓгфПьЕиаоИФСЫЃЌЙўЙўЃЁ
дйЫМПМвЛИіЮЪЬтЃЌЮЊЪВУДprevlenЕФГЄЖШвЊУДЪЧ1зжНквЊУДЪЧ5зжНкФиЃПЮЊЩЖУЛга2зжНкЁЂ3зжНкЁЂ4зжНкетаЉжаМфЬЌЕФГЄЖШФиЃПвЊНтД№етИіЮЪЬтОЭв§ГіСЫНёЬьЕФвЛИіЙиМќЮЪЬтЃКСЌЫјИќаТЮЪЬтЁЃ СЌЫјИќаТЮЪЬтЪдЯыетбљвЛжждіМгНкЕуЕФГЁОАЃК ШчЙћдкбЙЫѕСаБэЕФЭЗВПдіМгвЛИіаТНкЕуЃЌВЂЧвГЄЖШДѓгк254зжНкЃЌЫљвдЦфКѓУцНкЕуЕФprevlenБиаыЪЧ5зжНкЃЌШЛЖјдкдіМгаТНкЕужЎЧАЦфprevlenЪЧ1зжНкЃЌБиаыНјааРЉеЙЃЌМЋЖЫЧщПіЯТШчЙћвЛжБЖМашвЊРЉеЙФЧУДНЋВњЩњСЌЫјЗДгІЃК
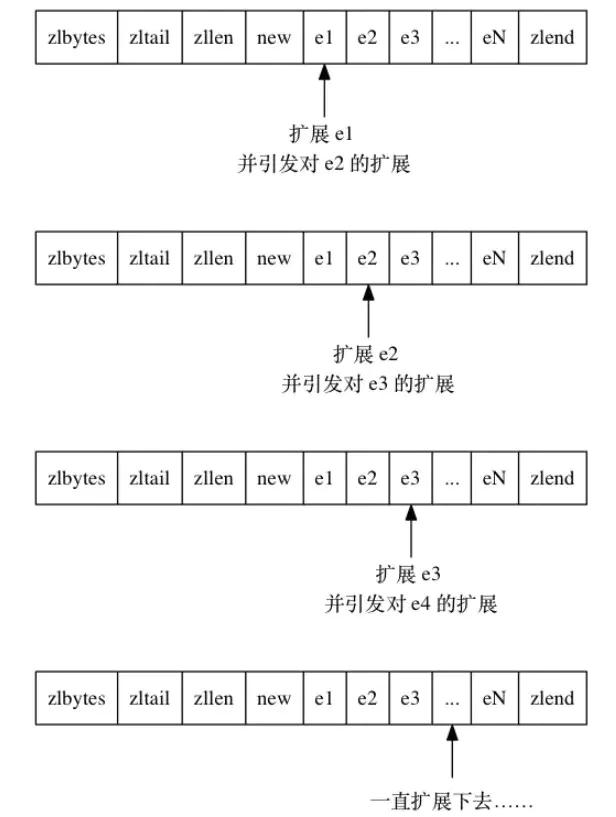
ЪдЯыСэЭтвЛжжЩОГ§НкЕуЕФГЁОАЃК ШчЙћашвЊЩОГ§ЕФНкЕуЪБаЁНкЕуЃЌИУНкЕуЧАУцЕФНкЕуЪЧДѓНкЕуЃЌетбљЕБАбаЁНкЕуЩОГ§ЪБЃЌЦфКѓУцЕФНкЕуОЭвЊБЃГжЦфЧАУцДѓНкЕуЕФГЄЖШЃЌУцСйзХРЉеЙЕФЮЪЬтЃК
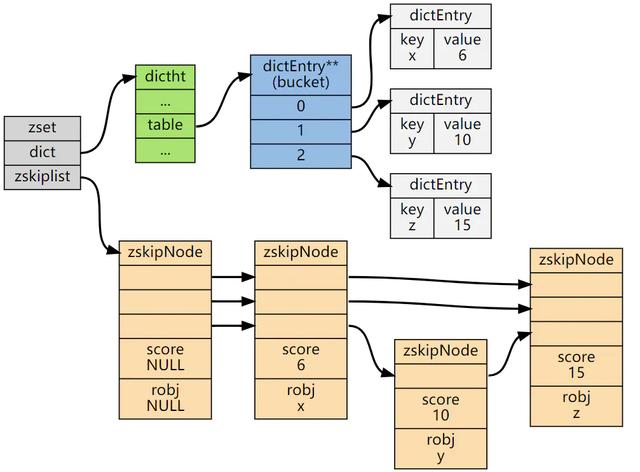
РэНтСЫСЌЫјИќаТЮЪЬтЃЌдйРДПДПДЮЊЪВУДвЊУД1зжНквЊУД5зжНкЕФЮЪЬтАЩЃЌШчЙћЪЧ2-4зжНкФЧУДПЩФмВњЩњСЌЫјЗДгІЕФИХТЪОЭИќДѓСЫЃЌЯрЗДжБНгИјЕНзюДѓ5зжНкЛсДѓДѓНЕЕЭСЌЫјИќаТЕФИХТЪЃЌЫљвдБЪепвВШЯЮЊетжжФкДцЕФаЁаЁРЫЗбвВЪЧжЕЕУЕФЁЃ ДгziplistЕФЩшМЦРДПДЃЌбЙЫѕСаБэВЂВЛЩУГЄаоИФВйзїЃЌетбљЛсЕМжТФкДцПНБДЮЪЬтЃЌВЂЧвЕБбЙЫѕСаБэДцДЂЕФЪ§ОнСПГЌЙ§ФГИіуажЕжЎКѓВщевжИЖЈдЊЫиДјРДЕФБщРњЫ№КФвВЛсдіМгЁЃ 0x09.ЬИЬИRedisЕФZsetКЭЬјдОСДБэЮЪЬтZSetНсЙЙЭЌЪБАќКЌвЛИізжЕфКЭвЛИіЬјдОБэЃЌЬјдОБэАДscoreДгаЁЕНДѓБЃДцЫљгаМЏКЯдЊЫиЁЃзжЕфБЃДцзХДгmemberЕНscoreЕФгГЩфЁЃСНжжНсЙЙЭЈЙ§жИеыЙВЯэЯрЭЌдЊЫиЕФmemberКЭscoreЃЌВЛРЫЗбЖюЭтФкДцЁЃ typedef struct zset { dict *dict; zskiplist *zsl;} zset;
ZSetжаЕФзжЕфКЭЬјБэВМОжЃК
9.1 ZSetжаЬјдОСДБэЕФЪЕЯжЯИНкЬјБэЪЧвЛИіИХТЪаЭЕФЪ§ОнНсЙЙЃЌдЊЫиЕФВхШыВуЪ§ЪЧЫцЛњжИЖЈЕФЁЃWillam PughдкТлЮФжаУшЪіСЫЫќЕФМЦЫуЙ§ГЬШчЯТЃК - жИЖЈНкЕузюДѓВуЪ§ MaxLevelЃЌжИЖЈИХТЪ pЃЌ ФЌШЯВуЪ§ lvl ЮЊ1
- ЩњГЩвЛИі0~1ЕФЫцЛњЪ§rЃЌШєr<pЃЌЧвlvl<MaxLevel ЃЌдђlvl ++
- жиИДЕк 2 ВНЃЌжБжСЩњГЩЕФr >p ЮЊжЙЃЌДЫЪБЕФ lvl ОЭЪЧвЊВхШыЕФВуЪ§ЁЃ
ТлЮФжаЩњГЩЫцЛњВуЪ§ЕФЮБТыЃК
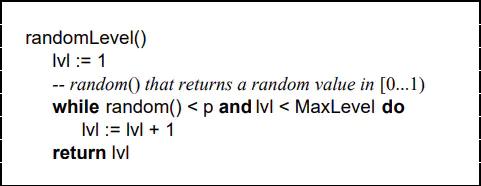
дкRedisжаЖдЬјБэЕФЪЕЯжЛљБОЩЯвВЪЧзёбетИіЫМЯыЕФЃЌжЛВЛЙ§гаЮЂаЁВювьЃЌПДЯТRedisЙигкЬјБэВуЪ§ЕФЫцЛњдДТыsrc/z_set.cЃК /* Returns a random level for the new skiplist node we are going to create. * The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL * (both inclusive), with a powerlaw-alike distribution where higher * levels are less likely to be returned. */int zslRandomLevel(void) { int level = 1; while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) level += 1; return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;}
ЦфжаСНИіКъЕФЖЈвхдкredis.hжаЃК #define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
ПЩвдПДЕНwhileжаЕФЃК (random()&0xFFFF) < (ZSKIPLIST_P*0xFFFF)
ЕквЛблПДЕНетИіЙЋЪНЃЌвђЮЊЩцМАЮЛдЫЫугааЉВявьЃЌашвЊбаОПвЛЯТAntirezЮЊЪВУДЪЙгУЮЛдЫЫуРДетУДаДЃП

зюПЊЪМЕФВТВтЪЧrandom()ЗЕЛиЕФЪЧИЁЕуЪ§[0-1]ЃЌгкЪЧКѕдкЯпевСЫИіИЁЕуЪ§зЊЖўНјжЦЕФЙЄОпЃЌЪфШы0.25ПДСЫЯТНсЙћЃК
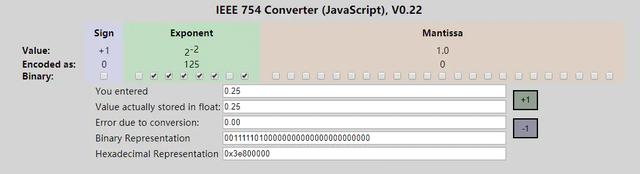
ПЩвдПДЕН0.25ЕФ32bitзЊЛЛ16НјжЦНсЙћЮЊ0x3e800000ЃЌШчЙћгы0xFFFFзігыдЫЫуНсЙћЪЧ0ЃЌКУЯёвВЗћКЯдЄЦкЃЌдйЪдвЛИі0.5:

ПЩвдПДЕН0.5ЕФ32bitзЊЛЛ16НјжЦНсЙћЮЊ0x3f000000ЃЌШчЙћгы0xFFFFзігыдЫЫуНсЙћЛЙЪЧ0ЃЌВЛЗћКЯдЄЦкЁЃ ЮвгЁЯѓжаCгябдЕФmathПтКУЯёВЂУЛгажБНгrandomКЏЪ§ЃЌЫљвдОЭШЅRedisдДТыжаевевПДЃЌгкЪЧЯТдиСЫ3.2АцБОДњТыЃЌвВВЂУЛгаевЕНrandom()ЕФЪЕЯжЃЌВЛЙ§евЕНСЫЦфЫћМИИіЕиЗНЕФгІгУЃК random()дкdict.cжаЕФЪЙгУ
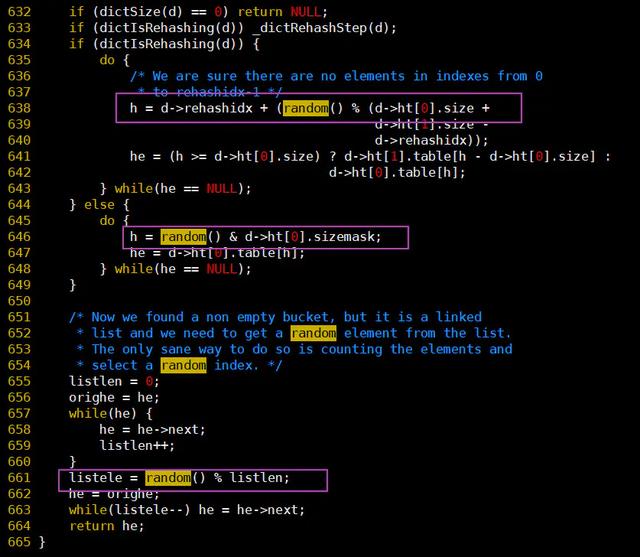
random()дкcluster.cжаЕФЪЙгУ
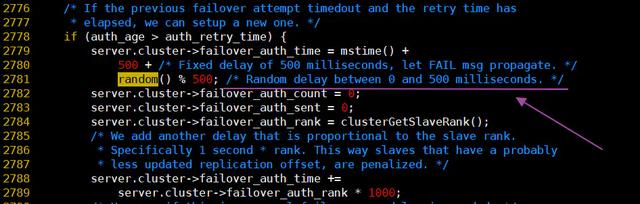
ПДЕНетРяЕФШЁФЃдЫЫуЃЌКѓжЊКѓОѕЕиЗЂЯждвдЮЊrandom()ЪЧИі[0-1]ЕФИЁЕуЪ§ЃЌЕЋЪЧЯждкПДРДЪЧuint32ВХЖдЃЌетбљAntirezЕФЪНзгОЭКУРэНтСЫЁЃ ZSKIPLIST_P*0xFFFF
гЩгкZSKIPLIST_P=0.25ЃЌЫљвдЯрЕБгк0xFFFFгввЦ2ЮЛБфЮЊ0x3FFFЃЌМйЩшrandom()БШНЯОљдШЃЌдкНјаа0xFFFFИп16ЮЛЧхСужЎКѓЃЌЕЭ16ЮЛШЁжЕОЭТфдк0x0000-0xFFFFжЎМфЃЌетбљwhileЮЊецЕФИХТЪжЛга1/4ЁЃИќвЛАуЕиЫЕЮЊецЕФИХТЪЮЊ1/ZSKIPLIST_PЁЃ ЖдгкЫцЛњВуЪ§ЕФЪЕЯжВЂВЛЭГвЛЃЌживЊЕФЪЧЫцЛњЪ§ЩњГЩЃЌLevelDBжаЖдЬјБэВуЪ§ЕФЩњГЩДњТыЃК template <typename Key, typename Value>int SkipList<Key, Value>::randomLevel() { static const unsigned int kBranching = 4; int height = 1; while (height < kMaxLevel && ((::Next(rnd_) % kBranching) == 0)) { height++; } assert(height > 0); assert(height <= kMaxLevel); return height;}uint32_t Next( uint32_t& seed) { seed = seed & 0x7fffffffu; if (seed == 0 || seed == 2147483647L) { seed = 1; } static const uint32_t M = 2147483647L; static const uint64_t A = 16807; uint64_t product = seed * A; seed = static_cast<uint32_t>((product >> 31) + (product & M)); if (seed > M) { seed -= M; } return seed;}
ПЩвдПДЕНleveldbЪЙгУЫцЛњЪ§гыkBranchingШЁФЃЃЌШчЙћжЕЮЊ0ОЭдіМгвЛВуЃЌетбљЫфШЛУЛгаЪЙгУИЁЕуЪ§ЃЌЕЋЪЧвВЪЕЯжСЫИХТЪЦНКтЁЃ ЮвУЧКмШнвзПДГіЃЌВњЩњдНИпЕФНкЕуВуЪ§ГіЯжИХТЪдНЕЭЃЌЮоТлШчКЮВуЪ§змЪЧТњзуУнДЮЖЈТЩдНДѓЕФЪ§ГіЯжЕФИХТЪдНаЁЁЃ ШчЙћФГМўЪТЕФЗЂЩњЦЕТЪКЭЫќЕФФГИіЪєадГЩУнЙиЯЕЃЌФЧУДетИіЦЕТЪОЭПЩвдГЦжЎЮЊЗћКЯУнДЮЖЈТЩЁЃУнДЮЖЈТЩЕФБэЯжЪЧЩйЪ§МИИіЪТМўЕФЗЂЩњЦЕТЪеМСЫећИіЗЂЩњЦЕТЪЕФДѓВПЗжЃЌ ЖјЦфгрЕФДѓЖрЪ§ЪТМўжЛеМећИіЗЂЩњЦЕТЪЕФвЛИіаЁВПЗжЁЃ
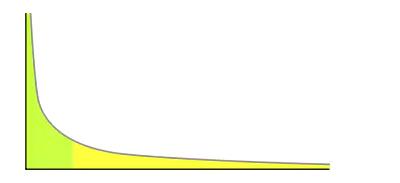
УнДЮЖЈТЩгІгУЕНЬјБэЕФЫцЛњВуЪ§РДЫЕОЭЪЧДѓВПЗжЕФНкЕуВуЪ§ЖМЪЧЛЦЩЋВПЗжЃЌжЛгаЩйЪ§ЪЧТЬЩЋВПЗжЃЌВЂЧвИХТЪКмЕЭЁЃ ЖЈСПЕФЗжЮіШчЯТЃК - НкЕуВуЪ§жСЩйЮЊ1ЃЌДѓгк1ЕФНкЕуВуЪ§ТњзувЛИіИХТЪЗжВМЁЃ
- НкЕуВуЪ§ЧЁКУЕШгк1ЕФИХТЪЮЊp^0(1-p)ЁЃ
- НкЕуВуЪ§ЧЁКУЕШгк2ЕФИХТЪЮЊp^1(1-p)ЁЃ
- НкЕуВуЪ§ЧЁКУЕШгк3ЕФИХТЪЮЊp^2(1-p)ЁЃ
- НкЕуВуЪ§ЧЁКУЕШгк4ЕФИХТЪЮЊp^3(1-p)ЁЃ
- вРДЮЕнЭЦНкЕуВуЪ§ЧЁКУЕШгкKЕФИХТЪЮЊp^(k-1)(1-p)
ШчЙћвЊЧѓНкЕуЕФЦНОљВуЪ§ЃЌФЧУДвВОЭзЊЛЛГЩСЫЧѓИХТЪЗжВМЕФЦкЭћЮЪЬтСЫЃЌСщЛъЛЪжДѓАздйДЮЩЯЯпЃК

|




 - VIPЙКТђ - ЪжЛњАц - аЁКкЮн - еОЕуАяжњ - Л§ЗжЙцдђ - Л§ЗжГфжЕ - гАТЅБІ - ЙВЯэЕъЦЬ - ЦДЭХаЁГЬађ - АдЦСДѓЪІ - ЛюЖЏБІ - вўЫНУтд№ - ИќаТШежО - ЩчШКжБВЅ - ЩчШКЛњЦїШЫ - ЮЂИЛЭј
( ЖѕICPБИ2021020606КХ )
- VIPЙКТђ - ЪжЛњАц - аЁКкЮн - еОЕуАяжњ - Л§ЗжЙцдђ - Л§ЗжГфжЕ - гАТЅБІ - ЙВЯэЕъЦЬ - ЦДЭХаЁГЬађ - АдЦСДѓЪІ - ЛюЖЏБІ - вўЫНУтд№ - ИќаТШежО - ЩчШКжБВЅ - ЩчШКЛњЦїШЫ - ЮЂИЛЭј
( ЖѕICPБИ2021020606КХ )






зюаТЦРТл
ВщПДШЋВПЦРТл(1)