
> source: https://www.flickr.com/people/22402885@N00
ЪЧЕФЃЌжЛаш10ЗжжгМДПЩПЊЪМДІРэФњЕФЕквЛИіДѓЪ§ОнМЏЃЁ
дкБОЮФжаЃЌЮвНЋЯђФњеЙЪОШчКЮдкОпБИвЛЖЈPythonБГОАЕФЧАЬсЯТЧсЫЩНјШыДѓЪ§ОнСьгђЁЃ
ПЊЪМетвЛаЁТУГЬЕФзюМбЕуЪЧЪзЯШСЫНтЪВУДЪЧДѓЪ§ОнЁЃ Д№АИЪЕМЪЩЯШЁОігкМЦЫуЛњЕФRAMДѓаЁКЭДІРэЫйЖШЁЃ ЖдгкГЃЙцPCЃЌГЌЙ§8GBЛђ16GBЕФШЮКЮФкШнЖМКмФбДІРэЁЃ ЙЋЫОЕФЛњЦїПЩФмЛЙПЩвдОзНРИќЖрЁЃ вђДЫЃЌДѓЪ§ОнЛљБОЩЯЪЧШЮКЮЬЋДѓЖјЮоЗЈвдГЃЙцЗНЪНДІРэЕФЪ§ОнМЏЁЃ
ФЧУДЮвУЧШчКЮДІРэДѓЪ§ОнФиЃП ЯдШЛЃЌвЛжжЗНЗЈЪЧЙКТђИќЖрЕФRAMКЭИќЧПДѓЕФДІРэЦїЁЃ ЕЋетЪЧЗЧГЃАКЙѓЕФЃЌЖјЧвВЛЪЧПЩРЉеЙЕФНтОіЗНАИЁЃ ШчЙћЪ§ОнМЏКмДѓЃЈ> 1TBЃЉЃЌдђПЩФмвВВЛЦ№зїгУЁЃ ЖјЪЧгавЛИіИќКУЕФПЩЩьЫѕНтОіЗНАИЁЃ ЫќНЋЪ§ОнМЏКЭЙЄзїИКдиЛЎЗжЕНЖрЬЈМЦЫуЛњ/МЦЫуЕЅдЊЩЯЁЃ ЕЋетВЂВЛвтЮЖзХФњашвЊЙКТђгВМўВЂздааСЌНгЛњЦїЁЃ авдЫЕФЪЧЃЌгаЛЅСЊЭјЗўЮёПЩвдЮЊЮвУЧЬсЙЉЭъећЕФМЦЫуЛљДЁМмЙЙЃЌЫцЪБПЩгУЁЃ
вЛжжетбљЕФЗўЮёЪЧAmazon AWSЃЌЫќПЩвдзтгУБивЊЪ§СПЕФМЦЫуЕЅдЊРДДІРэШЮКЮЪ§СПЕФЪ§ОнЁЃ МЦЫуЕЅдЊЮЛгкAmazonЗўЮёЦїЩЯЃЌЫцЪБПЩвдЪЙгУЁЃ ЪЙгУAWSЗўЮёЕФГЩБОЪЧЭъШЋЭИУїЕФЃЌВЂЧвЪЧАДУПаЁЪБУПЕЅЮЛМЦЫуЕФЁЃ ВЛгУЕЃаФЃЌдкДЫЪОР§жадЫааЪзДЮДѓЪ§ОнЗжЮіЕФзмЗбгУгІЕЭгк4УРдЊЁЃ
ЛАЫфетУДЫЕЃЌШУЮвУЧПЊЪМЙЄзїЃЁ
ВНжш1ЪЧДДНЈвЛИіAmazon AWSеЫЛЇЃК
1aЁЃ зЊЕНhttps://aws.amazon.com/ВЂДДНЈвЛИіеЪЛЇ
> Make an AWS account
1bЁЃ Г§СЫЭЈГЃЕФаХЯЂЭтЃЌФњЛЙашвЊЪфШыаХгУПЈЯъЯИаХЯЂЁЃ етЪЧзЂВсЕФзюКѓвЛВНЁЃ ЮЊСЫМьВщФњЕФаХгУПЈЪЧЗёецЪЕЃЌAmazon AWSНЋДгФњЕФеЫЛЇжавЛДЮадПлГ§1 $ЃЈЮвКмЬжбсЃЉЁЃ
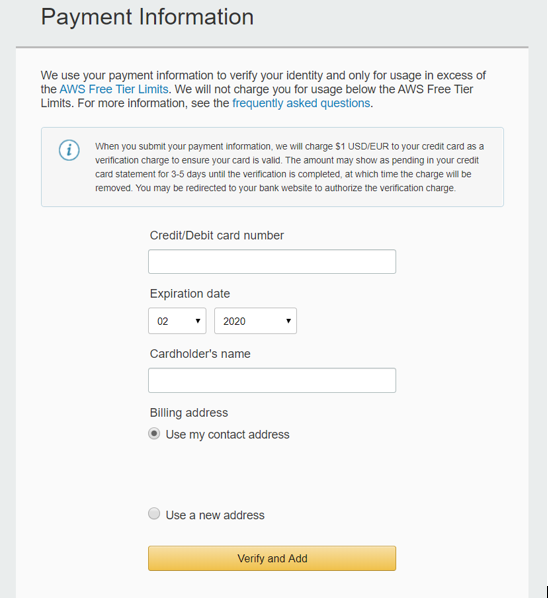
> Provide Credit Card information
дкеЪЛЇЩшжУЙ§ГЬжаЃЌбЁдёФњЕФЮЛжУЮЊЃКУРЙњЮїВПЃЈЖэРеИджнЃЉЃЈетВЛЪЧЧПжЦадЕФЃЌЕЋВЛЛсдьГЩЩЫКІЃЉ
Ек2ВНЪЧЦєЖЏФњЕФМЏШК
2aЁЃ ШКМЏЪЧвЛЖбВЂаадЫааЕФМЦЫуЛњЪЕР§/ДІРэЦїЕФДњУћДЪЁЃ ЕЧТМЕНФњЕФAWSеЫЛЇЃЌШЛКѓзЊЕНзѓЩЯНЧЕФЗўЮёЃЌШЛКѓЪфШыEMRЁЃ етДњБэElastic Map ReduceЃЌетЪЧвЛЯюгУгкВЂааМЦЫуЕФAmazonЗўЮёЁЃ
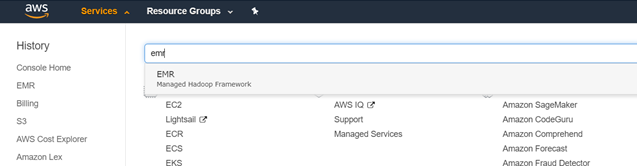
> Amazon offers a lot of services, choose EMR
2bЁЃ НјШыEMRКѓЃЌзЊЕНзѓВрУцАхжаЕФ"ШКМЏ"ЃЌШЛКѓЕЅЛї"ДДНЈШКМЏ"
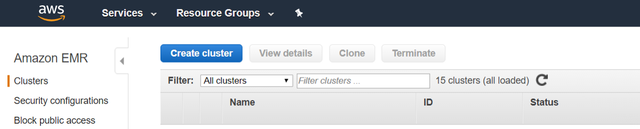
> Start making a Cluster
2cЁЃ ШЛКѓЕЅЛї"зЊЕНИпМЖбЁЯю"ЃЌШЗБЃФњЕФЦєЖЏФЃЪНЩшжУЮЊ"ШКМЏ"ЁЃ
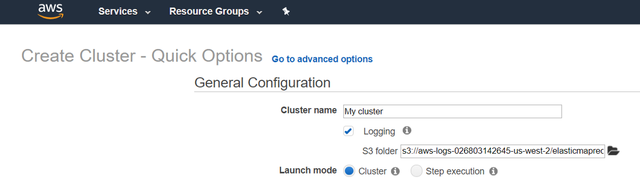
> Go to advanced options
ЪфШы"ИпМЖбЁЯю"КѓЃЌНЋЬюаД4ИівГУцЃЌвдгыЯТУцЯрЭЌЕФЗНЪННјааЩшжУЁЃ
2dЁЃ дкЕквЛвГЃЈШэМўКЭВНжшЃЉжаЃЌШЗБЃЪЙгУзюаТЕФEMRАцБОЃЌВЂбЁдёСЫSparkЃЌHiveКЭHadoopЁЃ ЭЌЪБбЁдёZepellinЃЌHueЃЌGangliaКЭPigЪЧвЛИіКУжївтЁЃ ЕЅЛїЯТвЛВНЁЃ
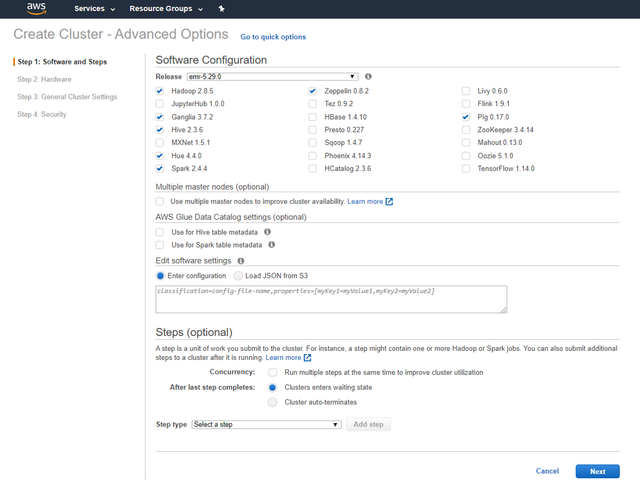
> 1st page of Cluster advanced options ЁЊ Software
2eЁЃ дкЕкЖўвГЃЈгВМўЃЉжаЃЌЮвУЧгІИУбЁдёЪЕР§/ДІРэЦїРраЭКЭЪЕР§Ъ§СПЁЃ Amazon AWSЬсЙЉСЫаэЖрВЛЭЌЕФЪЕР§/ДІРэЦїРраЭЁЃ ЫќУЧОпгаВЛЭЌЕФФПЕФКЭМлИёЃЌвђДЫзюКУЕїВщФФжжХфжУзюЪЪКЯФњЕФШЮЮёЁЃ
дкДЫЪОР§жаЃЌЮвбЁдёСЫЮхИіM5.xlargeДІРэЦїЃЈ1ИіжїЪЕР§КЭ4ИіCoreЪЕР§ЃЉЁЃ гыЦеЭЈPCЯрБШЃЌЫќЬсЙЉСЫДѓдМ10БЖЕФRAMЁЃ ЪТЪЕжЄУїЃЌетбљЕФДІРэзувдДІРэ12 GBКЭ2500ЭђааЕФЪ§ОнМЏЁЃ
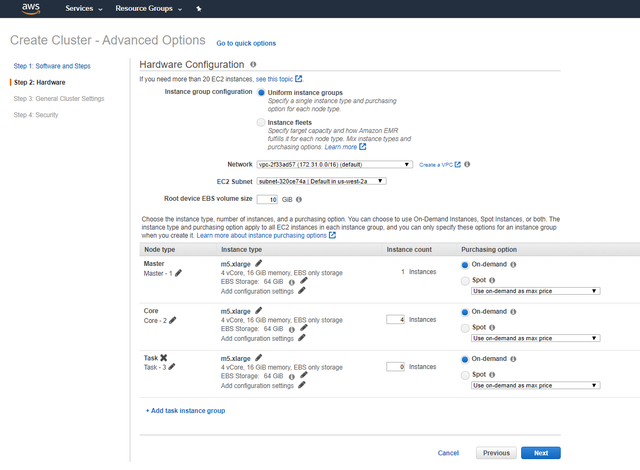
> 2nd page of Cluster advanced options ЁЊ Hardware setup
2fЁЃ дк"ШКМЏ"ИпМЖбЁЯюЕФЕкШ§вГЃЈ"ГЃЙцШКМЏЩшжУ"ЃЉжаЃЌЮвУЧгІИУИјШКМЏУќУћ
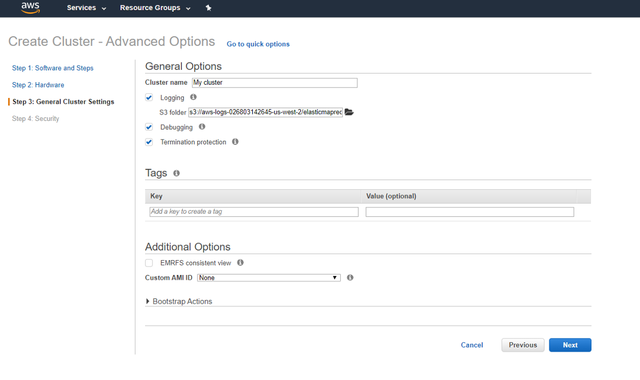
> 3rd page of Cluster advanced options ЁЊ General Settings
2ПЫ дк"ШКМЏ"ИпМЖбЁЯюЕФЕк4вГЃЈ"АВШЋад"ЃЉжаЃЌПЩвдЩшжУАВШЋадХфжУЁЃ ЮвУЧВЛЛсЖдДЫЬиБ№ЙизЂЃЌвђДЫЮвбЁдёСЫУЛгаEC2УмдПЖдЕФМЬајЁЃ ФњПЩвддкДЫДІдФЖСгаЙиEC2УмдПЖдЕФИќЖраХЯЂЁЃ
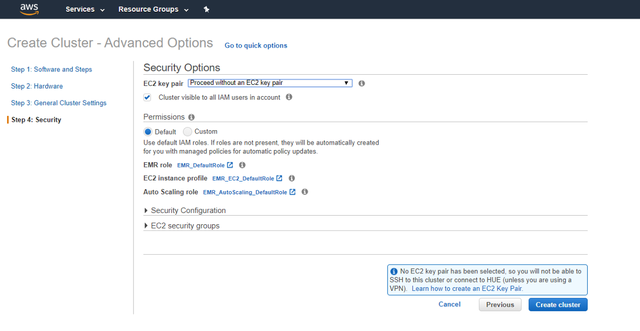
> 4th page of Cluster advanced options ЁЊ Security
2аЁЪБ ЯждкФњЕФМЏШКвбЩшжУЭъБЯЃЌЕЅЛї"ДДНЈМЏШК"ЃЌНЋГіЯжвдЯТЦСФЛ
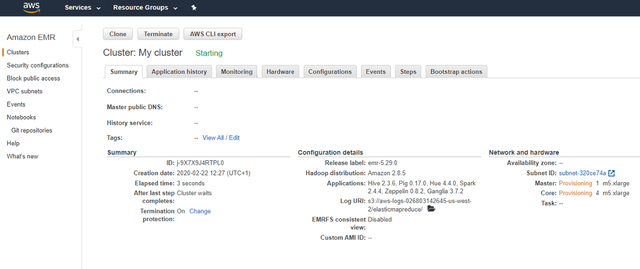
> Your cluster is almost ready
2iЁЃ ЕЅЛїзѓДАИёжаЕФШКМЏЁЃ ШКМЏЕФзДЬЌЮЊе§дкЦєЖЏЁЃ ШКМЏзМБИОЭаїКѓЃЌзДЬЌНЋИќИФЮЊ"ЕШД§"ЃЈШКМЏОЭаїЃЉЁЃ ЭЌбљЃЌвЛЕЉзМБИКУЪЙгУШКМЏЃЌШКМЏУћГЦХдБпЕФТЬЩЋдВШІНЋБфГЩвЛИіЭъећЕФТЬЩЋдВШІЁЃ ЧыЫцЪБЫЂаТвГУцЃЌвдМьВщдВШІЪЧЗёБфЮЊТЬЩЋЁЃ

> Wait for the full green circle to appear

> Your cluster is ready!
2jЁЃ ЯждкЃЌЮвУЧгІИУЮЊФњЕФДњТыЩшжУЙЄзїЧјЁЃ Amazon EMRдкИУЦНЬЈжаМЏГЩСЫJupyterБЪМЧБОЁЃ дкзѓДАИёЩЯЃЌЕЅЛї"БЪМЧБО"ЃЌШЛКѓЕЅЛї"ДДНЈБЪМЧБО"ЁЃ
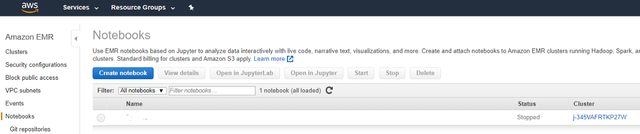
> Start a Jupyter Notebook
2kЁЃ ЮЊФњЕФБЪМЧБОУќУћЃЌШЛКѓЕЅЛї"бЁдё"ЃЈдк"ШКМЏ"ЯТЃЉвдНЋФњЕФБЪМЧБОИНМгЕНИеДДНЈЕФШКМЏЁЃ
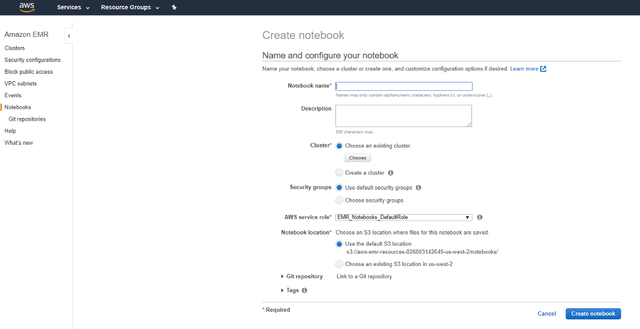
> Give your Notebook a Name
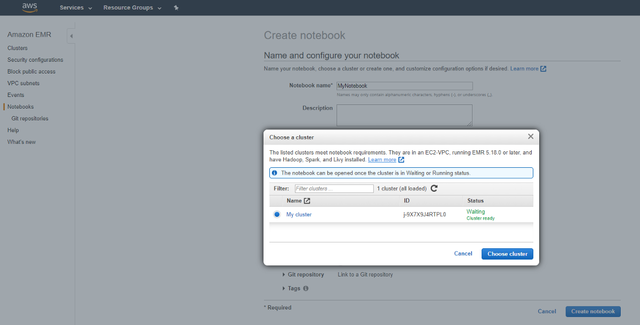
> Attach your Notebook to a Cluster
2Щ§ ШЛКѓЕЅЛїбЁдёШКМЏЃЌШЛКѓЕЅЛїДДНЈБЪМЧБОЁЃ ФњЕФБЪМЧБОЕчФдвВНЋашвЊМИЗжжгРДзМБИЁЃ зМБИОЭаїКѓЃЌЫќНЋзДЬЌДг"ПЊЪМ"ИќИФЮЊ"ОЭаї"ЁЃ ЕЅЛїЩЯЗНЕФдкJupyterжаДђПЊЁЃ
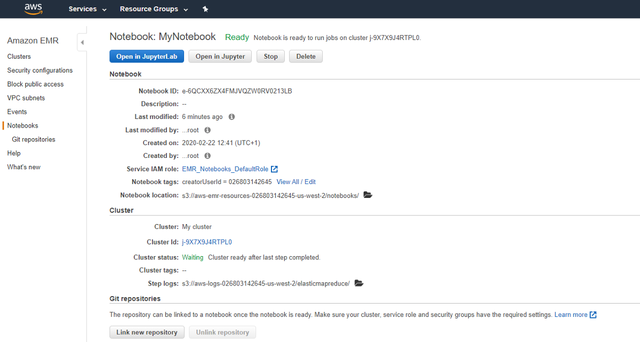
> Wait until your Notebook is Ready
2m ЯждкЃЌФњЕФJupyter NotebookНЋдкСэвЛИіфЏРРЦїДАПкжаДђПЊЁЃ ДђПЊБЪМЧБОЕчФдКѓЃЌЧыШЗБЃЕЅЛїФкКЫ/ИќИФФкКЫ/ PySparkЁЃ ФЧЪЧЕк2ВНЕФзюКѓВПЗжЁЃ
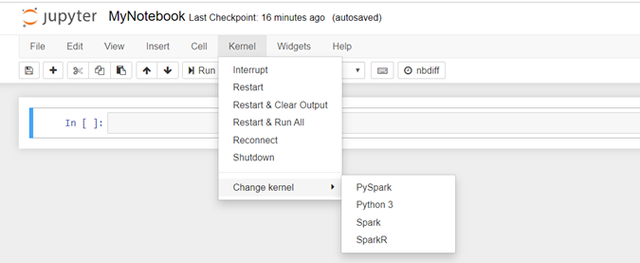
> Set your Jupyter Notebook to PySpark
ВНжш3ЪЧзМБИФњЕФЃЈДѓЃЉЪ§Он
3aЁЃ ЗЕЛиЕквЛИіAWSвГУцЃЌзЊЕНServicesВЂевЕНS3ЁЃ S3ЪЧбЧТэбЗЬсЙЉЕФвЛИіЗЧГЃДѓЕФдЦЪ§ОнПтЁЃ етЪЧгІИУДцДЂФњЕФЪ§ОнЕФЮЛжУЁЃ
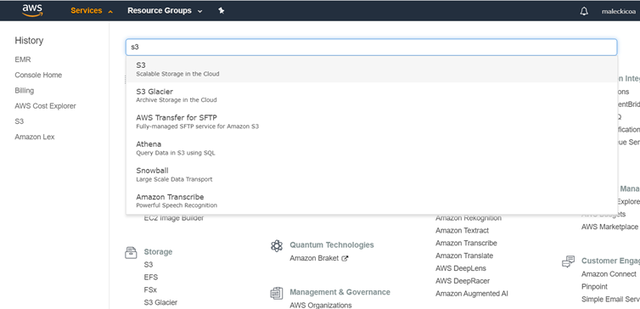
> Go to Amazon S3
3bЁЃ дкS3жаЃЌЕЅЛї"ДДНЈДцДЂЭА"ЁЃ етЪЧвЛИіДцДЂПтЃЌФњНЋдкЦфжаЩЯдиЪ§ОнЁЃ
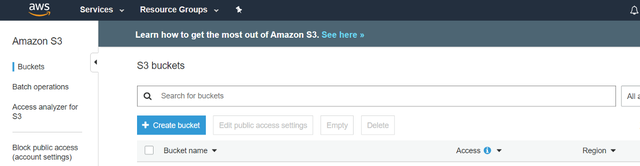
> Create a Bucket inside Amazon S3
3cЁЃ ИјФњЕФДцДЂЭАЦ№вЛИіЮЈвЛЕФУћзжЁЃ Amazon S3ЩЯЕФСНИіДцДЂЭАВЛФмЙВЯэЯрЭЌЕФУћГЦ
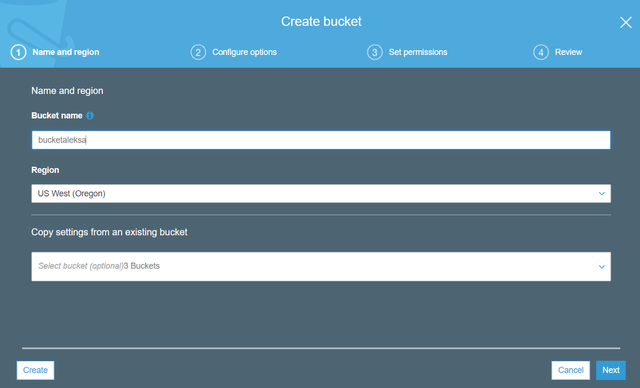
> Give your S3 Bucket a unique Name
3dЁЃ ЕЅЛїДцДЂЭАвдНЋЦфДђПЊ
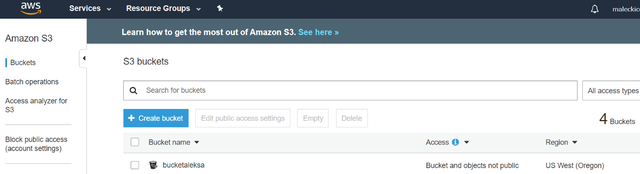
> Open your Bucket
3eЁЃ ФњЯждкПЩвдНЋЪ§ОнЬэМгЕНДцДЂЭАжаЁЃ ЖдгкаЁгк160 GBЕФЮФМўЃЌФњжЛашНЋЫќУЧЭЯЗХЕНДцДЂЭАжаМДПЩЁЃ ЃЈвЊЩЯДЋДѓгк160 GBЕФЪ§ОнЃЌФњБиаыЪЙгУAWS CLIЃЌAWS SDKЛђAmazon S3 REST APIЃЉ
ОЭБОНЬГЬЖјбдЃЌФњПЩвдМЬајЪЙгУДЫащФтЪ§ОнМЏЁЃ НЋЦфЯТдиЕНБОЕиМЦЫуЛњЃЌШЛКѓНЋЦфЩЯДЋЕНДцДЂЭАЁЃ
ащФтЪ§ОнМЏжЛгаМИИіMBЃЌвђДЫВЛЪЧДѓЪ§ОнЁЃ ШчЙћФњгЕгаЪЪЕБЕФДѓЪ§ОнМЏЃЌдђПЩвдЫцвтЪЙгУЫќЖјВЛЪЧащФтЪ§ОнМЏЁЃ
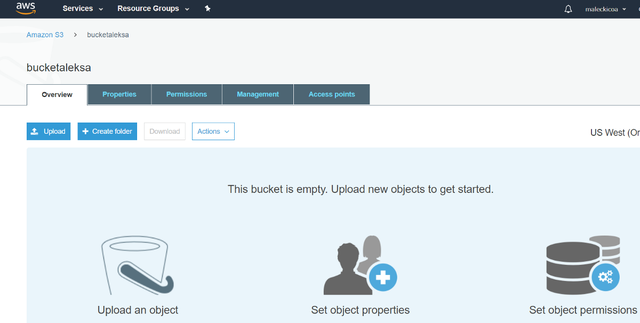
> Upload the Data to your Bucket
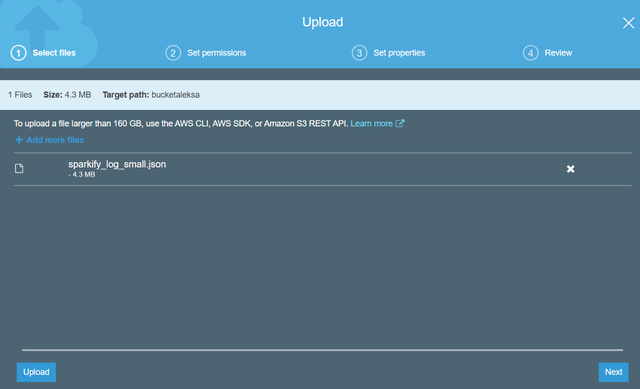
> Your Data will appear in the Bucket
3ТЅ МьВщФњЕФЪ§ОнЪЧЗёдкДцДЂЭАжа
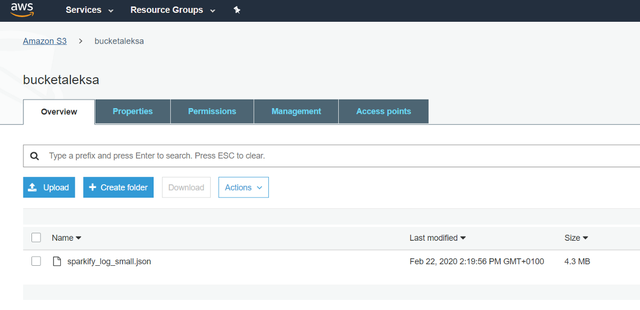
> Your data is in the bucket and ready to analyse
3ПЫ ЯждквЛЧаЖМзМБИКУНјааЗжЮіСЫЁЃ Ъ§ОнЕФТЗОЖОпгавдЯТФЃЪНЃК" s3nЃК//ФњЕФДцДЂЭАУћГЦ/ФњЕФЮФМўУћЁЃРЉеЙУћРраЭ"ЁЃ
ФњНЋЪЙгУИУТЗОЖНЋS3Ъ§ОнЕМШыJupyter Notebook
Ек4ВНЪЧзюКѓНјааДѓЪ§ОнЗжЮіЃЁ
4aЁЃ ЪзЯШЕМШыЛљБОЕФPySparkШэМўАќЁЃ
PySparkЪЧвЛИіAPIЃЌжМдкжЇГждкSparkЩЯдЫааЕФPythonЁЃ SparkЪЧвЛИіМЏШКМЦЫуПђМмЃЌНќРДМИКѕЪЧBig DataЕФЭЌвхДЪЁЃ МђЖјбджЎЃЌSparkе§дкаЕїЗжЩЂдкЖрИіДІРэЕЅдЊжаЕФЙЄзїИКдиЁЃ вЊжДааДѓЪ§ОнВЂгыSparkНЛЛЅЃЌФњЛЙПЩвдбЁдёScalaЃЌJavaЛђRДњЬцPythonЃЈPySparkЃЉЁЃ
гЩгкЮвЖдPythonЪьЯЄЃЌвђДЫГігкБОЪОР§ЕФФПЕФЃЌЮвбЁдёСЫPySparkЁЃ ФњЛсЗЂЯжPySparkгыБОЛњPythonгяЗЈЗЧГЃЯрЫЦЃЌЕЋЪЧШчЙћгіЕНЮЪЬтЃЌПЩвддкДЫДІВщевЁЃ
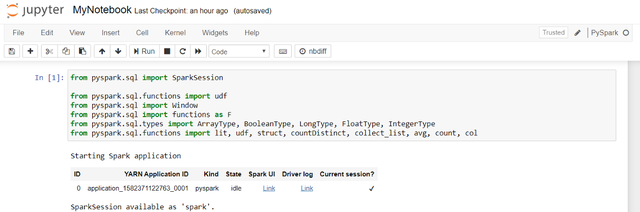
> Import PySpark packages
4bЁЃ ДДНЈвЛИіSparkЛсЛАЃЌВЂЪЙгУЯШЧАжЦзїЕФPathДгФњЕФДцДЂЭАжаЕМШыЪ§ОнЁЃ
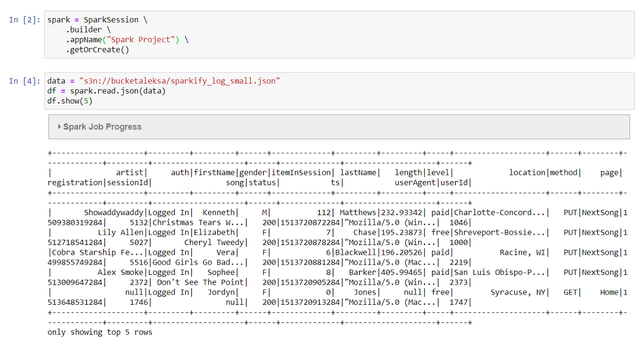
> Import the Data into the Jupyter Notebook
4cЁЃ зіФуЕФЗжЮіЁЃ ФњПЩвддкPySparkЛђSQLгяЗЈжЎМфНјаабЁдёЁЃ ШчЙћФњбЁдёЪЙгУSQLгяЗЈЃЌЧыВЛвЊЭќМЧжЦзїСйЪББэЁЃ ФњжЛФмЖдСйЪББэдЫааВщбЏЃЌЖјВЛФмжБНгЖдPySparkЪ§ОнжЁдЫааВщбЏЁЃ
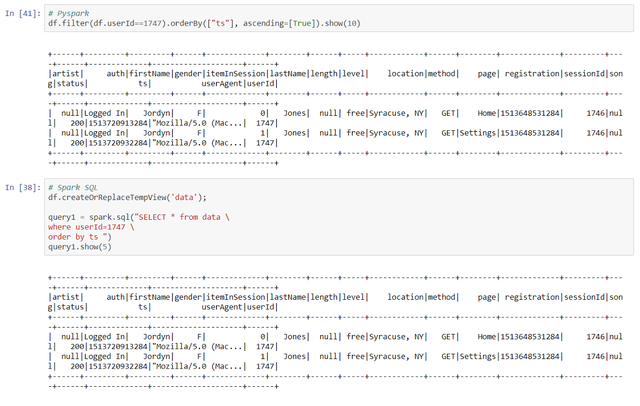
> Choose between native PySpark or SQL syntax to wrangle your data
ШчЙћФњЯыЖдЪ§ОндЫааMLЫуЗЈЃЌЯТУцЪЧвЛИігаЙиШчКЮдкPySparkжаЭъГЩВйзїЕФЪОР§ЁЃ
Ек5ВНЪЧжежЙЛсЛА
5aЁЃ ЭъГЩЗжЮіКѓЃЌЧыШЗБЃжежЙМЏШКЁЃ ЗёдђПЩФмЛсЕМжТИпАКЕФЗбгУЁЃ ЗЕЛиЗўЮё/ EMR /ШКМЏЃЌШЛКѓЕЅЛїжежЙЁЃ
> Don't forget to terminate your clusters
5bЁЃ ШКМЏашвЊМИЗжжгВХФмЙиБе
> Check if the cluster is terminating
5cЁЃ жЎКѓЃЌФњгІИУЭЃжЙЛђЩОГ§БЪМЧБОЃЌВЂЩОГ§S3ДцДЂЭАЁЃ жЛвЊНЋЫќУЧБЃДцдкAWSЗўЮёЦїЩЯЃЌетСНепЖМЛсВњЩњЃЈЪЕМЪЩЯЪЧКмаЁЕФЃЉГЩБОЁЃ вђДЫЃЌШчЙћФњецЕФВЛашвЊЫќУЧЃЌЧыНЋЦфЩОГ§ЁЃ дкЩОГ§БЪМЧБОжЎЧАЃЌЧыВЛвЊЭќМЧдкБОЕиЯТдиБЪМЧБОЃЌЗёдђФњНЋЖЊЪЇДњТыЁЃ
5d ЩОГ§ФњЕФS3ДцДЂЭА
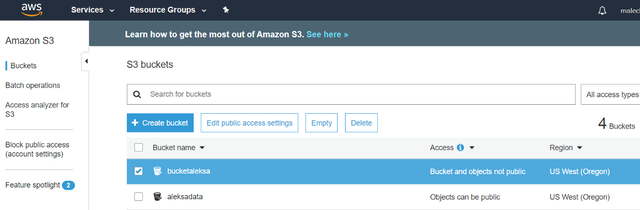
> Delete your Buckets
5eЁЃ зюКѓвЛВНЪЧЭЈЙ§зЊЕНФњЕФеЪЛЇУћ/ЮвЕФНсЫуаХЯЂжааФРДМьВщФњЕФеЫЕЅ
> Check your Billing Dashboard
5f ШчЧАЫљЪіЃЌШчЙћФње§ШЗжДааСЫЫљгаВНжшЃЌдђДЫСЗЯАЕФзмеЪЕЅВЛЛсГЌЙ§3УРдЊЃЌетЛЙВЛАќРЈ1УРдЊЕФаХгУПЈжЇЦБЗбгУЁЃ ЃЈе§ШчФњдкЯТУцПДЕНЕФФЧбљЃЌЮвЩшЗЈВњЩњСЫИќИпЕФГЩБОЃЌЕЋетНіНіЪЧвђЮЊЮвНЋШКМЏдЫааСЫМИЬьЁЃЃЉ
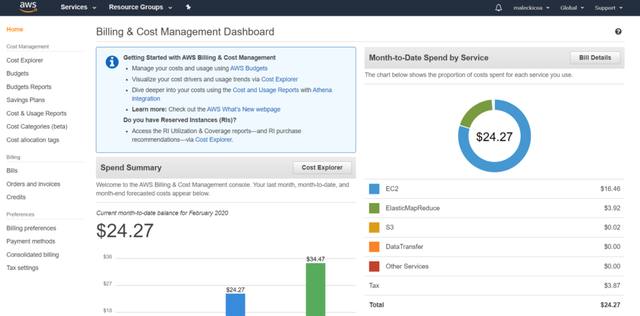
> The Billing Dashboard provides some nice visualizations of your AWS Costs
змНс
ЮвУЧвбОНсЪјСЫаЁаЁЕФТУГЬЃЌЫљвдШУЮвУЧПьЫйзмНсвЛЯТЮвУЧвбОКИЧЕФЩЯЪіВНжшЃК
ЁЄ ПЊЩшвЛИіAmazon AWSеЫЛЇ
ЁЄ ЪЙгУAWS EMRЗўЮёЩшжУВЂМЄЛюМЏШК
ЁЄ жЦзїJupyterБЪМЧБОВЂНЋЦфгыШКМЏСЌНг
ЁЄ НЋФњЕФЪ§ОнЩЯДЋЕНAmazon S3
ЁЄ дЫааЗжЮі
ОЭЪЧетбљЃЁ :)ЙЇЯВФњПЊЪМНјааЪзДЮДѓЪ§ОнЗжЮіЃЁЃЁ
ШчЙћФње§ШЗжДааСЫЫљгаВйзїЃЌдђДѓдМашвЊ10ЗжжгВХФмЭъГЩЩЯЪіХфжУВНжшЁЃ ЯЃЭћБОЮФЖдФњгаЫљАяжњЃЌВЂзЃФњдкЮДРДЕФДѓЪ§ОнбаОПжаШЁЕУГЩЙІЃЁ
(БОЮФЗвыздMihajlovic AleksaЕФЮФеТЁЖBig Data in 10 MinutesЁЗЃЌВЮПМЃКhttps://towardsdatascience.com/big-data-in-10-minutes-bead3c012ba4)
| 









 - VIPЙКТђ - ЪжЛњАц - аЁКкЮн - еОЕуАяжњ - Л§ЗжЙцдђ - Л§ЗжГфжЕ - гАТЅБІ - ЙВЯэЕъЦЬ - ЦДЭХаЁГЬађ - АдЦСДѓЪІ - ЛюЖЏБІ - вўЫНУтд№ - ИќаТШежО - ЩчШКжБВЅ - ЩчШКЛњЦїШЫ - ЮЂИЛЭј
( ЖѕICPБИ2021020606КХ )
- VIPЙКТђ - ЪжЛњАц - аЁКкЮн - еОЕуАяжњ - Л§ЗжЙцдђ - Л§ЗжГфжЕ - гАТЅБІ - ЙВЯэЕъЦЬ - ЦДЭХаЁГЬађ - АдЦСДѓЪІ - ЛюЖЏБІ - вўЫНУтд№ - ИќаТШежО - ЩчШКжБВЅ - ЩчШКЛњЦїШЫ - ЮЂИЛЭј
( ЖѕICPБИ2021020606КХ )
зюаТЦРТл
ВщПДШЋВПЦРТл(1)